





Si Google voit en OpenAI son plus grand adversaire dans la course à l'IA, la vraie menace pour l'entreprise pourrait venir de la communauté open source. Une note interne d'un chercheur de Google rappelle que les deux gros poissons du domaine ne disposent pas de la « formule magique » pour les IA génératives. Et que, comme pour les images, les alternatives open source risquent de rapidement faire de l'ombre aux services commerciaux.
« Nous ne sommes pas en mesure de gagner cette course à l'armement, pas plus qu'OpenAI », écrit le chercheur. Pendant que les grosses boites se tirent la bourre et avancent dans l'ombre, la communauté open source progresse à grands pas. Les modèles de langages (le « moteur » permettant de faire tourner un service comme ChatGPT) ne sont plus réservés à de gros serveurs ou à une poignée de passionnés fortunés empilant les 4090ti dans leurs garages. Il est désormais possible d'utiliser un modèle de langage localement sur un Pixel 6 à une vitesse plus que correcte, ou d'installer son ChatGPT local sur son Mac M1 en une petite demi-heure.

LLaMA, Vicuna, Alpaca : comment faire tourner un modèle de langage sur son Mac ?
Les travaux open source ont véritablement commencé avec la fuite du modèle LLaMA de Meta, censé rester réservé à la recherche, mais ayant rapidement été partagé sur des forums en torrent. S'il s'agissait d'une base brute, les bidouilleurs ont réussi à l'affiner et à le faire tourner sur des machines d'entrée de gamme en quelques jours. Les plus petites entreprises progressent également : on a récemment vu arriver Dolly 2 ou le StableLM des équipes derrière le générateur d'images Stable Diffusion. Ces deux modèles sont open source et complètement indépendants étant donné qu'ils ne se basent pas sur les travaux de Meta.
Si nos modèles conservent un léger avantage en termes de qualité, l'écart se réduit étonnamment vite. Les modèles open source sont plus rapides, plus personnalisables, plus privés et plus performants. Ils font des choses avec 100 $ et des modèles à 13 milliards de paramètres que nous avons du mal à faire avec 10 millions de dollars et 540 milliards de paramètres. Et ils le font en quelques semaines, pas en quelques mois.
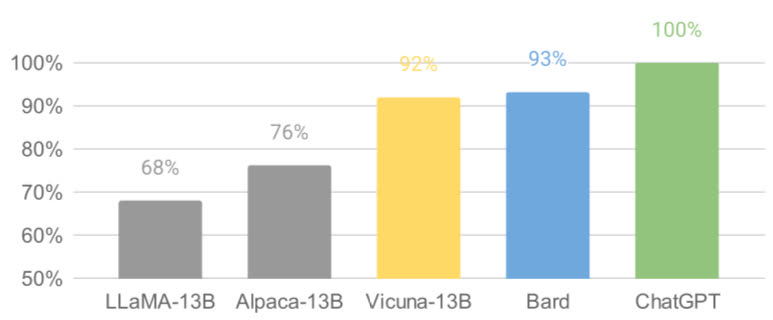
Les modèles open source sont loin d'être des versions au rabais par rapport à ce que proposent les grandes entreprises. Vicuna (un dérivé de LLaMA) promet des résultats équivalents à 90 % à ceux de ChatGPT. L'université de Berkeley a récemment lancé Koala, un modèle de dialogue entièrement formé à partir de données librement accessibles. Plus de 50 % des utilisateurs préfèrent Koala ou n'ont pas de préférence face à ChatGPT.
Les performances s'améliorant donc à vitesse grand V, et GPT-4 ne devrait pas rester sur le podium des IA les plus compétentes très longtemps. En pleine effervescence, la communauté open source découvre chaque semaine des nouveautés techniques majeures à côté desquelles étaient passées OpenAI et Google.
De nombreuses idées nouvelles émanent de personnes ordinaires. La barrière à l'entrée pour la formation et l'expérimentation [de modèles de langage] est passée de la capacité totale d'un grand organisme de recherche à une personne, une soirée et un ordinateur portable puissant.
L'arrivée d'une alternative simple et open source est un vrai risque pour les deux entreprises. « Les gens ne paieront pas pour un modèle restreint alors que des alternatives gratuites et non réglementées sont comparables en termes de qualité », s'alarme le chercheur. Dolly 2.0 est libre et utilisable dans le cadre d'un usage commercial, un argument qui devrait séduire de nombreux potentiels clients.
Pour le chercheur, Google ne devrait pas essayer de faire mieux que la communauté open source mais plutôt travailler avec elle, quitte à ouvrir la porte sur ce qui se passe en cuisine. « Plus nous contrôlons étroitement nos modèles, plus nous rendons attrayantes les alternatives ouvertes. », écrit-il.
L'arrivée de formules open source rebat les cartes au niveau de la prudence vis-à-vis de la technologie. Si OpenAI et Google affirment tout deux vouloir avancer sagement pour éviter les abus, il est déjà trop tard : les modèles open source ne sont pas censurés et livrés sans garde-fous. Google doit donc repenser la manière dont elle se positionne sur le créneau et la valeur ajoutée de ses services.

La situation n'est pas sans rappeler ce qui s'est passé pour la génération d'images. Si le DALL-E d'OpenAI a impressionné les foules, l'alternative open source Stable Diffusion a rapidement pris le devant de la scène. Le service d'Open AI est désormais beaucoup moins attractif maintenant qu'il existe un concurrent gratuit et plus personnalisable. Son aspect libre lui a permis de s'enrichir de nombreuses intégrations et nouveautés qui font défaut au service privé.

DALL-E, Stable Diffusion (2/2) : des IA qui soulèvent de nombreuses questions
Le chercheur estime que Meta est le grand gagnant de la fuite de son modèle. Vu que LLaMA est à la base de nombreux travaux open source, rien ne l'empêche de les incorporer directement dans ses produits. Il plaide pour que Google cherche à s'imposer comme un leader de l'open source afin de mieux contrôler l'écosystème, à la manière de ce qu'elle a fait pour Chrome et Android. Tout cela pourrait passer par des intégrations visant à collaborer avec les acteurs open source.
Cela impliquera probablement de prendre des mesures désagréables […] Cela implique nécessairement de renoncer à un certain contrôle sur nos modèles. Mais ce compromis est inévitable. Nous ne pouvons pas espérer à la fois stimuler l'innovation et la contrôler.
Pour le chercheur, la question n'est pas de savoir ce que va faire OpenAI, qui commet les mêmes erreurs que Google en gardant tout sous clef. « Les alternatives open source peuvent et finiront par éclipser, à moins qu'ils ne changent de position. Sur ce point au moins, nous pouvons faire le premier pas. ».
Source :






.jpg){kind=link}