





Comme la course au gigahertz a pris fin, la course au multicore s'arrêtera bien aussi un jour. C'est du moins ce qu'a déclaré de directeur technique d'AMD pour les serveurs, Donald Newell. « La guerre du nombre de cores viendra un jour à finir. Je ne mettrai pas de date précise là-dessus, mais je ne compte pas moi-même voir 128 cores sur une matrice de serveur grand format d'ici la fin de la décennie. »
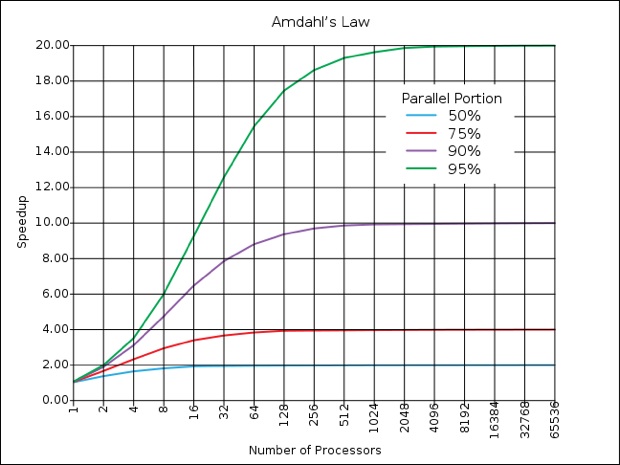
Et pour cause, selon la loi d'Amdahl, la portion parallèle des logiciels doit être de 75 % pour qu'une différence se fasse sentir avec 128 processeurs, le tout pour n'obtenir au mieux qu'une accélération par quatre (lire Le monde parallèle de Photoshop)
Les serveurs ont toutefois la tâche plus facile pour tirer parti des processeurs multiples, dans la mesure où chaque requête d'un poste client est susceptible de lancer une tâche du côté serveur, alors que les machines mono-utilisateurs doivent morceler les tâches pour obtenir un effet de calcul parallèle.
« Ça n'est pas irréaliste pour une feuille de route technologique, mais ça l'est pour une feuille de route d'usage, les contraintes en termes d'énergie auxquelles sont tenus les serveurs ne rendraient pas faisables des puces avec autant de cores. »
Le cadre d'AMD estime qu'Intel prendra la même direction. Sachant que celui-ci a passé 16 ans chez Intel avant de rejoindre AMD l'été dernier, il a sans doute de bonnes raisons de le penser. De quoi soulager quelque peu les développeurs sur lesquels toute la pression de l'accélération matérielle s'est focalisée, afin que leurs logiciels tirent le meilleur parti possible de ces multiples processeurs.
« Nous pensions que nous construirions un jour un processeur à 10 GHz », se souvient Newell, de l'époque où il travaillait chez Intel. « Ça n'est que lorsque nous nous sommes rendus compte qu'ils seraient si chauds qu'ils pourraient fondre la croûte terrestre, que nous avons préféré ne pas le faire. », plaisante-t-il.
L'après multicore, selon lui, consistera à équiper les processeurs de circuits dédiés au lieu de multiplier les processeurs génériques. Ce qui les fera ressembler à des systèmes-sur-une-puce (SoC), avec des sections dédiées à des tâches particulières, comme l'encryptage, le rendu vidéo, ou la gestion du réseau. « Il n'y a rien qui nous empêche d'ajouter des fonctionnalités précises sur une matrice afin de permettre des calculs plus efficaces. Vous devez vous attendre à l'émergence d'architectures hétérogènes, là où nous identifierons des fonctions qui sont largement utiles mais qui ne se retrouvent pas nécessairement dans une instruction que vous souhaiteriez ajouter à l'architecture x86. » De fait, ces unités fonctionneraient comme des co-processeurs. « Nous développons actuellement un jeu de techniques architecturales pour rendre cette intégration bien plus facile. »
AMD comme Intel ont commencé à poser des jalons dans ce sens, avec des produits qui mélangeront CPU et GPU sur une seule et même matrice. La gestion de l'énergie est un autre champ d'exploration : « Il fut un temps où ça n'était qu'une pensée après coup. Jusqu'en 2004, la valeur ne tenait qu'aux performances. » Mais rapidement les besoins en énergie des serveurs sont devenus préoccupants et les fabricants de processeurs ont pris en compte ce besoin dans leurs designs, des éléments qui ont également été mis à profit notamment pour les ordinateurs portables qui ont besoin de plus de puissance tout en consommant moins d'énergie.
Reste que le département marketing des fabricants aura quelque difficulté à faire briller leurs produits dans les diverses comparaisons : s'il était facile de comparer les cycles d'horloges ou le nombre de cores (pour toutes inappropriées que ces comparaisons aient pu être par ailleurs, entre processeurs RISC et CISC par exemple), la gestion de tâches dédiées sera plus délicate à évaluer de façon numérique
Et pour cause, selon la loi d'Amdahl, la portion parallèle des logiciels doit être de 75 % pour qu'une différence se fasse sentir avec 128 processeurs, le tout pour n'obtenir au mieux qu'une accélération par quatre (lire Le monde parallèle de Photoshop)
Les serveurs ont toutefois la tâche plus facile pour tirer parti des processeurs multiples, dans la mesure où chaque requête d'un poste client est susceptible de lancer une tâche du côté serveur, alors que les machines mono-utilisateurs doivent morceler les tâches pour obtenir un effet de calcul parallèle.
« Ça n'est pas irréaliste pour une feuille de route technologique, mais ça l'est pour une feuille de route d'usage, les contraintes en termes d'énergie auxquelles sont tenus les serveurs ne rendraient pas faisables des puces avec autant de cores. »
Le cadre d'AMD estime qu'Intel prendra la même direction. Sachant que celui-ci a passé 16 ans chez Intel avant de rejoindre AMD l'été dernier, il a sans doute de bonnes raisons de le penser. De quoi soulager quelque peu les développeurs sur lesquels toute la pression de l'accélération matérielle s'est focalisée, afin que leurs logiciels tirent le meilleur parti possible de ces multiples processeurs.
« Nous pensions que nous construirions un jour un processeur à 10 GHz », se souvient Newell, de l'époque où il travaillait chez Intel. « Ça n'est que lorsque nous nous sommes rendus compte qu'ils seraient si chauds qu'ils pourraient fondre la croûte terrestre, que nous avons préféré ne pas le faire. », plaisante-t-il.
L'après multicore, selon lui, consistera à équiper les processeurs de circuits dédiés au lieu de multiplier les processeurs génériques. Ce qui les fera ressembler à des systèmes-sur-une-puce (SoC), avec des sections dédiées à des tâches particulières, comme l'encryptage, le rendu vidéo, ou la gestion du réseau. « Il n'y a rien qui nous empêche d'ajouter des fonctionnalités précises sur une matrice afin de permettre des calculs plus efficaces. Vous devez vous attendre à l'émergence d'architectures hétérogènes, là où nous identifierons des fonctions qui sont largement utiles mais qui ne se retrouvent pas nécessairement dans une instruction que vous souhaiteriez ajouter à l'architecture x86. » De fait, ces unités fonctionneraient comme des co-processeurs. « Nous développons actuellement un jeu de techniques architecturales pour rendre cette intégration bien plus facile. »
AMD comme Intel ont commencé à poser des jalons dans ce sens, avec des produits qui mélangeront CPU et GPU sur une seule et même matrice. La gestion de l'énergie est un autre champ d'exploration : « Il fut un temps où ça n'était qu'une pensée après coup. Jusqu'en 2004, la valeur ne tenait qu'aux performances. » Mais rapidement les besoins en énergie des serveurs sont devenus préoccupants et les fabricants de processeurs ont pris en compte ce besoin dans leurs designs, des éléments qui ont également été mis à profit notamment pour les ordinateurs portables qui ont besoin de plus de puissance tout en consommant moins d'énergie.
Reste que le département marketing des fabricants aura quelque difficulté à faire briller leurs produits dans les diverses comparaisons : s'il était facile de comparer les cycles d'horloges ou le nombre de cores (pour toutes inappropriées que ces comparaisons aient pu être par ailleurs, entre processeurs RISC et CISC par exemple), la gestion de tâches dédiées sera plus délicate à évaluer de façon numérique





