Internet Archive a sorti il y a quelques jours une extension pour Chrome, capable d'aller puiser dans son stock de pages archivées lorsque vous tombez sur un message d'erreur au gré de vos déambulations sur le web. Les amateurs de Firefox ont également une telle solution.
Le cas le plus courant est l'erreur 404, lorsque la page correspondant à une URL a disparu, mais il en existe beaucoup d'autres qui ont la même conséquence pour l'internaute : une voie sans issue et un contenu disparu.
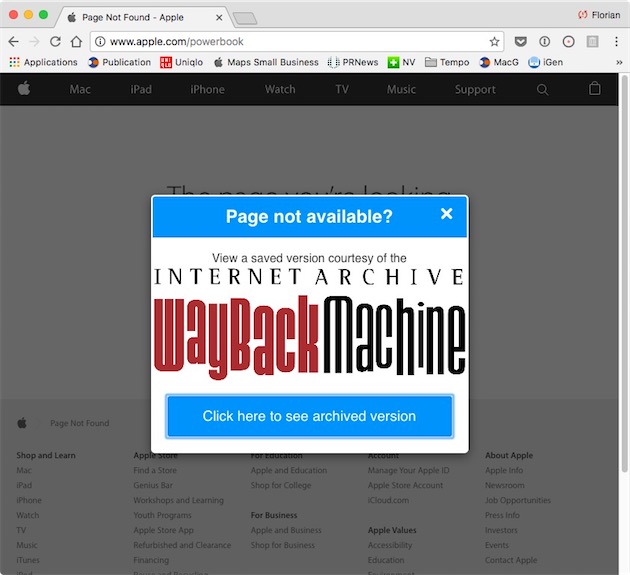
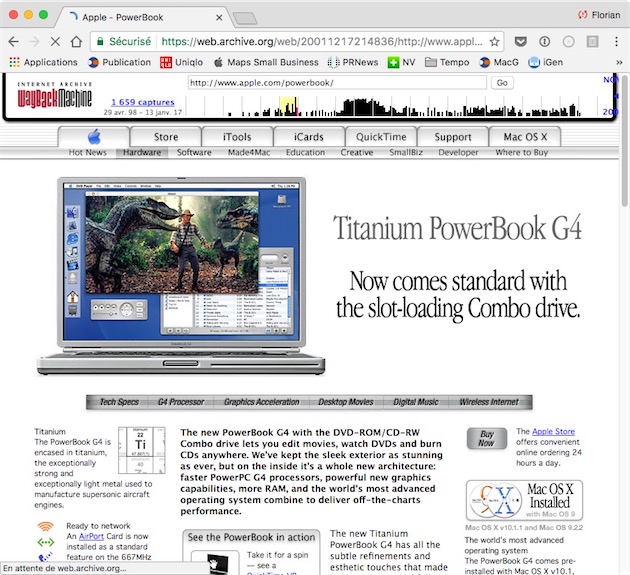
Lorsque l'extension détectera l'affichage de l'un de ces codes d'erreur, elle ira automatiquement interroger la base de données d'Internet Archive pour voir s'il n'existerait pas une version enregistrée de la page qui figurait à cet endroit.
Avec 20 ans d'activité et, à ce jour, plus de 279 milliards de pages web enregistrées puis archivées il y a peut-être une chance que la page disparu subsiste dans le fond constitué inlassablement par Internet Archive. Cette dernière insiste également sur les questions de confidentialité. L'extension n'exploitera pas votre historique de navigation et l'Internet Archive discute avec Google pour insérer des serveurs proxy de manière à opacifier l'origine des requêtes et les adresses IP.
Source :