





À chacun son tour. Quelques semaines après GPT-5.1, Gemini 3 et Opus 4.5, Mistral AI accouche d’une nouvelle famille de modèles d’intelligence artificielle. Mistral Large 3 représente le nec plus ultra avec un total de 675 milliards de paramètres. En pratique, le modèle est découpé en « experts » mobilisant 41 milliards de paramètres chacun. Sa fenêtre de contexte atteint 256 000 tokens, ce qui permet de lui faire ingérer d’un seul coup une grande quantité de données.
Multimodal, Mistral Large 3 vise les usages courants : analyse de documents, programmation, assistance personnelle, etc. Contrairement à Gemini ou GPT, c’est un modèle ouvert, publié sous licence Apache 2.0, librement modifiable et utilisable. Son créateur l’oppose ainsi à d’autres modèles de cette catégorie, notamment DeepSeek V3.1. Sans surprise, les benchmarks sélectionnés placent la techno française en tête dans la plupart des scénarios.
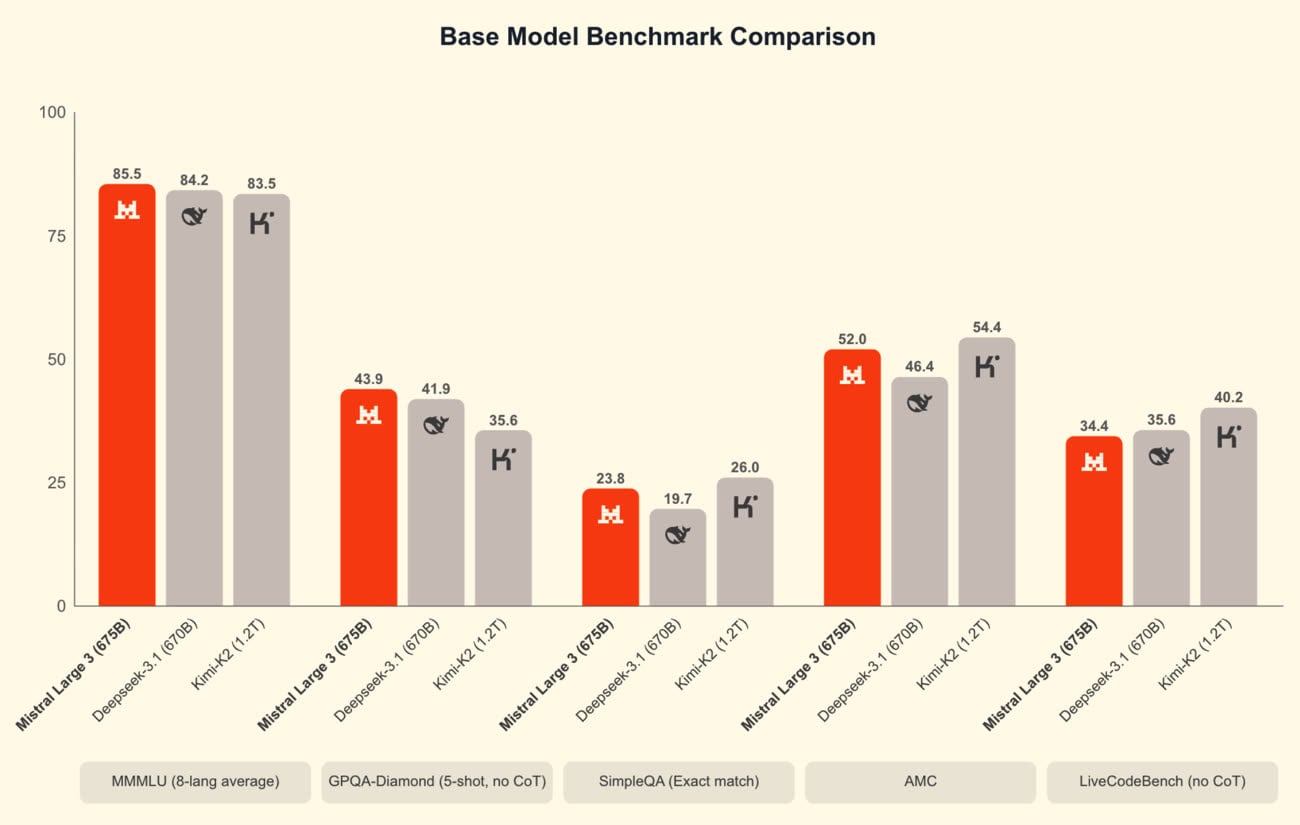
GPT-OSS, le modèle ouvert d’OpenAI qui compte jusqu’à 120 milliards de paramètres, ne fait pas partie des comparaisons pour une raison précise : il s’agit d’un modèle de raisonnement, qui traite chaque question via une « chaîne de pensée » censée produire de meilleures réponses. Une variante de Mistral Large 3 dédiée au raisonnement est promise pour bientôt.
Mistral Large 3 sera intégré prochainement à Le Chat, l’interface conversationnelle de l’éditeur, et il est déjà disponible sur plusieurs plateformes, dont Hugging Face. Le modèle demandant une puissance de calcul et une quantité de mémoire que seuls des serveurs peuvent offrir, Mistral propose aussi des versions condensées capables de tourner sur des machines grand public.
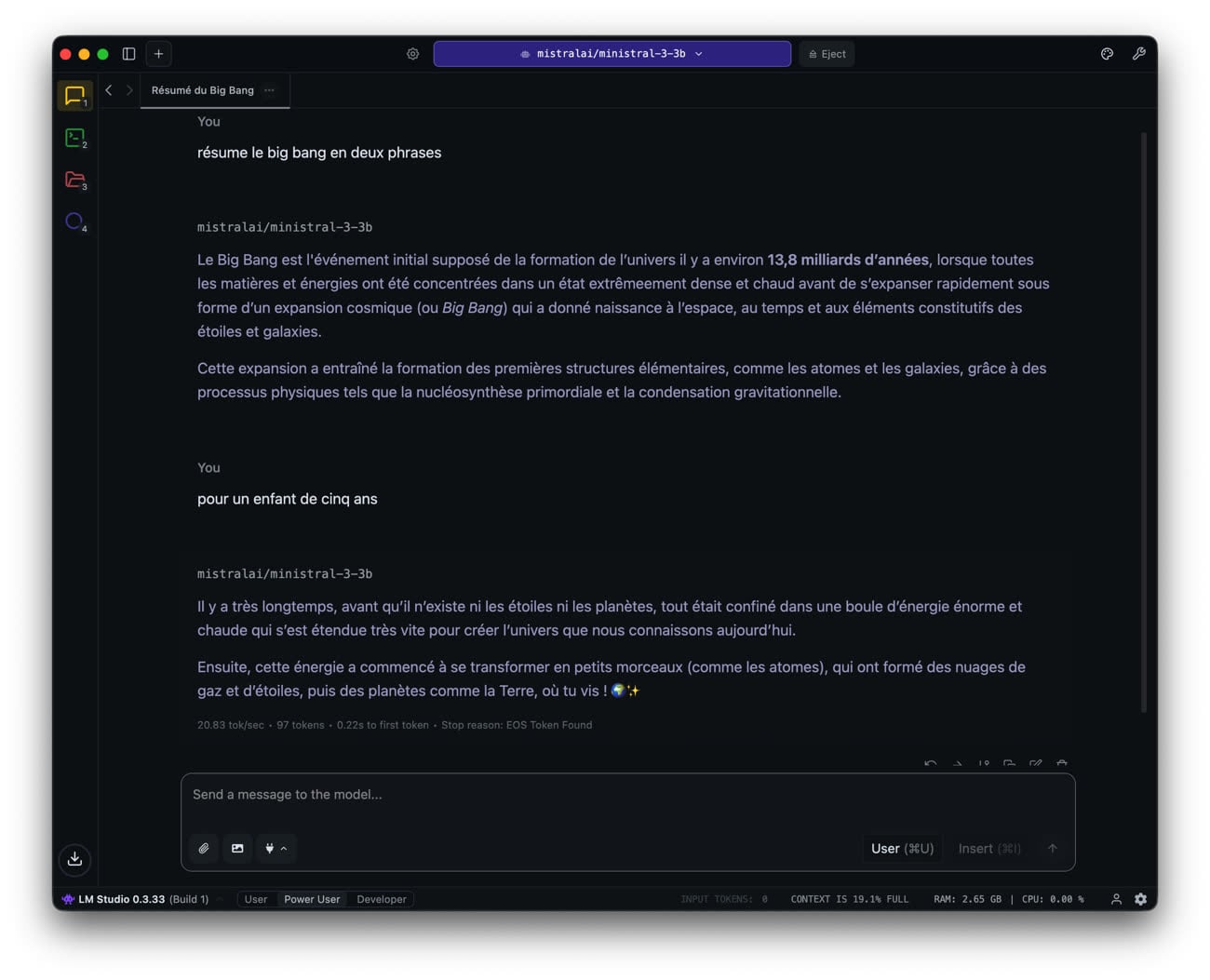
C’est la série Ministral 3, disponible en trois tailles (3 milliards, 8 milliards ou 14 milliards de paramètres) et en trois variantes : Base (pré-entraîné), Instruct (optimisé pour le chat) et Reasoning (pour les problèmes complexes). Le spécialiste de l’IA assure que cette nouvelle génération offre le meilleur rapport coût/performance parmi les modèles ouverts. Sur un MacBook Air M1, dans LM Studio, Ministral 3-3B en quantization 4 bits occupe un peu moins de 3 Go de RAM et la génération s’effectue à environ 22 tokens par seconde.

L'IA est là : le glossaire pour tout comprendre

Comment faire tourner DeepSeek-R1 (ou un autre LLM) sur votre Mac






