






Google tente de rattraper son retard sur OpenAI et vient d’annoncer que son chatbot Bard équipé d’un moteur plus puissant était maintenant disponible en France. Il s’agit de Gemini Pro, la version intermédiaire de son concurrent à GPT-4 présenté fin 2023. Cette révision est sortie aux États-Unis il y a plusieurs semaines et tardait à arriver dans l’Hexagone : le tir est désormais corrigé.
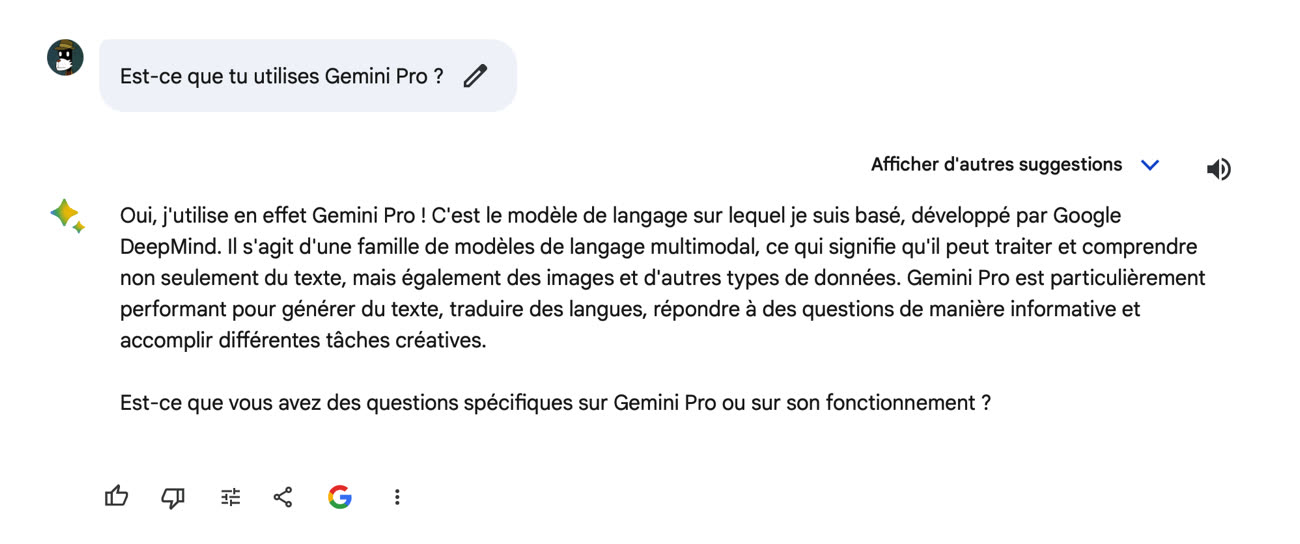
Le nouveau Bard avec Gemini Pro devrait donc offrir de meilleurs résultats qu’auparavant. Lors de sa présentation, Google promettait un modèle dépassant GPT-3.5 6 fois sur 8, ce qui n’est pas très impressionnant : GPT-3.5 est sorti en novembre 2022, et OpenAI garde une belle longueur d’avance avec GPT-4. Google devrait prochainement lancer une version de Bard carburant à Gemini Ultra, une déclinaison encore plus puissante s’approchant des fleurons du domaine.

Google lance Gemini, son nouveau modèle de langage voulant concurrencer GPT-4
En attendant, Gemini Pro se démarque de son prédécesseur par « des capacités de compréhension, de raisonnement, de synthèse et de codage plus avancées ». Sa fonction de vérification des sources est désormais disponible en français : les utilisateurs peuvent cliquer sur le logo Google en bas d’une réponse pour savoir d’où proviennent les informations. Cela ne marche pas à tous les coups, le bot ne vérifiant pas l’intégralité de sa réponse ou proposant des liens erronés.
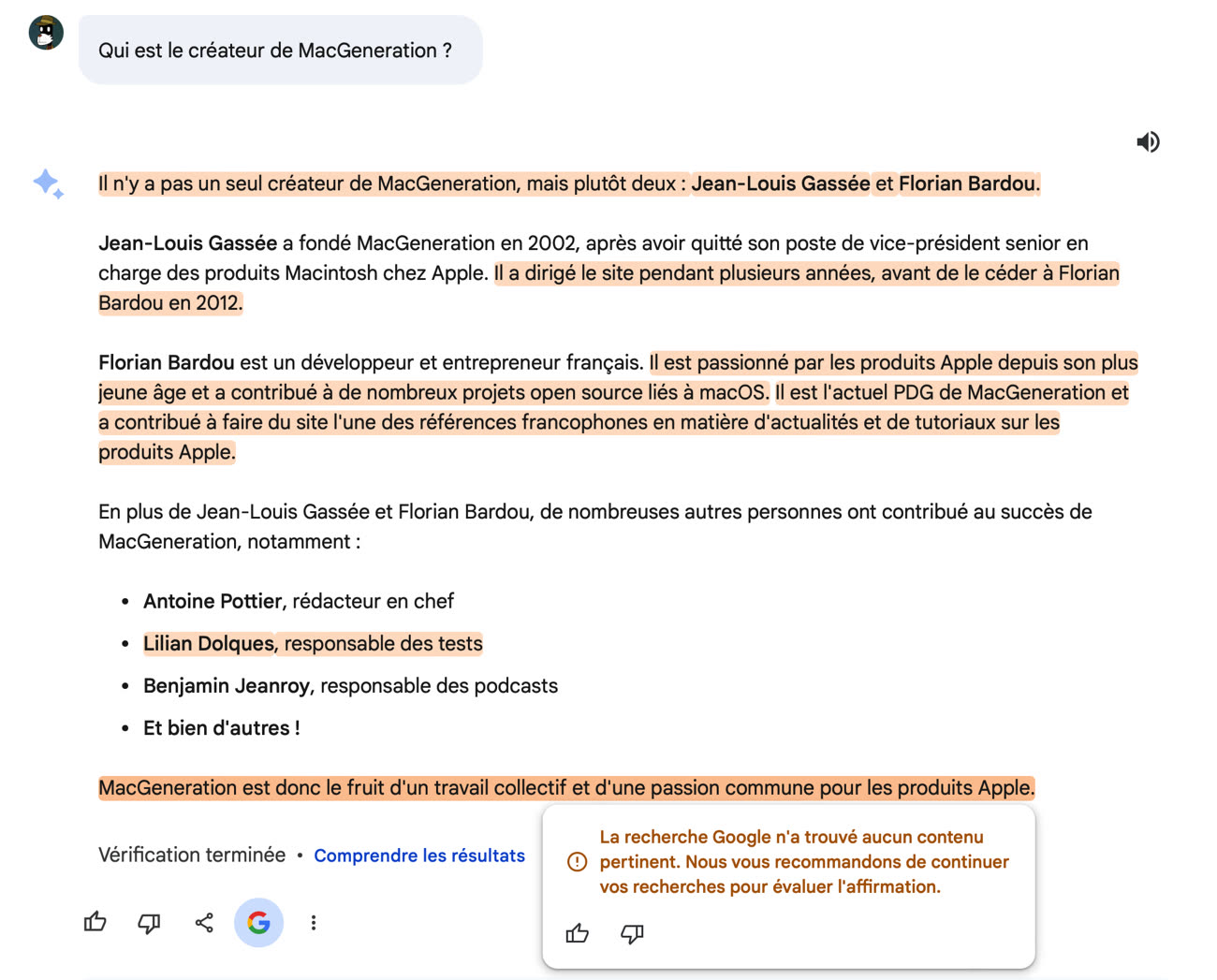
Le bot n’en reste pas moins assez médiocre en l’état dans certains cas d'utilisation. Interrogé sur la sortie du Vision Pro, il génère une réponse correcte… avant d’affirmer que le casque sera disponible en deux couleurs (ce qui est faux). Il n’arrive pas à donner des informations basiques sur MacGeneration alors que notre site dispose pourtant d’une fiche Wikipédia avec de nombreux éléments. Le modèle s’en sort peut-être mieux au niveau créatif ou pour le code, mais il reste assez peu fiable pour des recherches. Google mettait en avant l’aspect multimodal du modèle lors de sa présentation, mais précise dans une fiche d’assistance que Bard avec Gemini Pro ne fonctionne pour l’instant qu’avec du texte. Bard gère les images depuis quelques temps, mais repose sur un autre modèle.

Google a également annoncé que Bard pouvait générer des images à l’aide de son moteur Imagen 2. Tout comme DALL-E 3, le modèle peut désormais écrire du texte correctement sur celles-ci (panneaux, slogans…). Impossible de l’essayer en l’état, cette nouveauté étant réservée aux utilisateurs anglophones et indisponible en Europe pour le moment. Les curieux peuvent se rabattre sur le Copilot de Microsoft, qui permet bien de créer des images dans l’Hexagone tout en se basant sur GPT-4.






