





Malgré les fortes turbulences dans le domaine, Apple continue de plancher sur l’IA et vient de publier Pico-Banana-400K. Il s’agit d’un jeu de données comportant 400 000 exemples d’édition d’images guidée par texte. Il a été pensé pour améliorer les systèmes d’IA visant à retoucher des photos depuis une demande textuelle.

Apple explique avoir suivi avec intérêt l’évolution des modèles permettant d’éditer une photo avec du texte, citant par exemple les travaux de Google ou d’OpenAI. Cependant, elle note que les progrès ont pu être limités par l’absence de données d’entraînement tirées de vraies photos. Le but de Pico-Banana-400K est donc de corriger le tir avec un corpus massif, proprement annoté et construit sur d'authentiques clichés plutôt que sur des images artificielles générées de toutes pièces.
Pour cela, Apple a utilisé la base de données Open Images avant de les passer à la moulinette de Gemini-2.5 Flash. Celui-ci suggère des modifications (« change la couleur du ciel ») avant que le Nano-Banana de Google s’exécute. Gemini-2.5 Pro juge ensuite du résultat et met de côté les plus qualitatifs. Les résultats jugés trop insuffisant ne sont pas jetés, et Apple en a gardé environ 56 000 pour l’alignement de modèles, c’est-à-dire pour apprendre ce qui est bon et ce qui est moins bon.
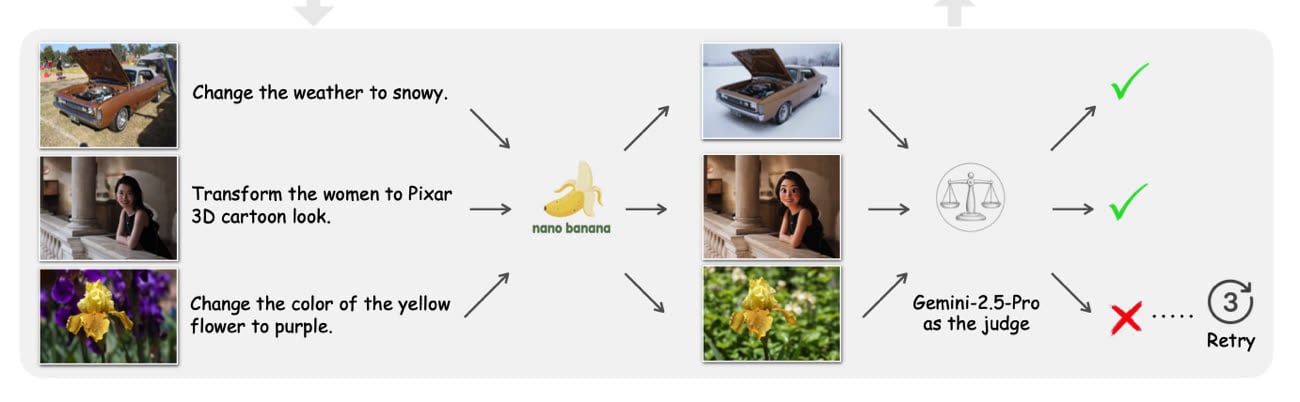
Le jeu comporte 35 catégories différentes. On y trouve des retouches simples (ajoute un objet, change une couleur) ou des transformations plus globales (change la météo). Sont également inclus des cas dans lesquels le style graphique ou le texte affiché sont modifiés. Il inclut aussi 72 000 dialogues d’édition multi-étapes, où une image est modifiée tour après tour. L’étude permet de voir que Nano-Banana n’est pas infaillible : s’il s’en sort bien 93 % du temps pour changer un style, la modification de texte ou le changement de place d’un objet ne fonctionne pas plus de 40 % du temps.
Apple mentionne dans le papier que fabriquer Pico-Banana-400K a coûté environ 100 000 dollars et que l’ensemble du corpus a été généré quasi intégralement sans annotation humaine manuelle. La base de données peut être téléchargée sur GitHub et est sous licence gratuite pour une utilisation non commerciale.






