





Apple publie de temps à autre ses travaux de recherche et deux nouveaux sont sortis ce mois-ci. L'un des documents — LLM in a flash — décrit des moyens pour utiliser de grands modèles de langage dans l'espace mémoire réduit d'un appareil tel qu'un smartphone. La capacité en RAM est très insuffisante pour stocker l'intégralité d'un modèle contenant des milliards d'entrées qui peuvent totaliser une dizaine de giga-octets.
Les chercheurs d'Apple proposent d'utiliser le stockage flash de l'appareil — par définition beaucoup plus conséquent — et de recourir à des méthodes ingénieuses pour limiter le poids des données chargées en RAM en réutilisant des choses déjà analysées lors de précédents traitements. Cela limite l'empreinte sur la mémoire vive et réduit le nombre et le temps des échanges entre le stockage flash et la RAM. La technique repose en outre sur la capacité des supports flash à transférer rapidement de gros blocs de données.
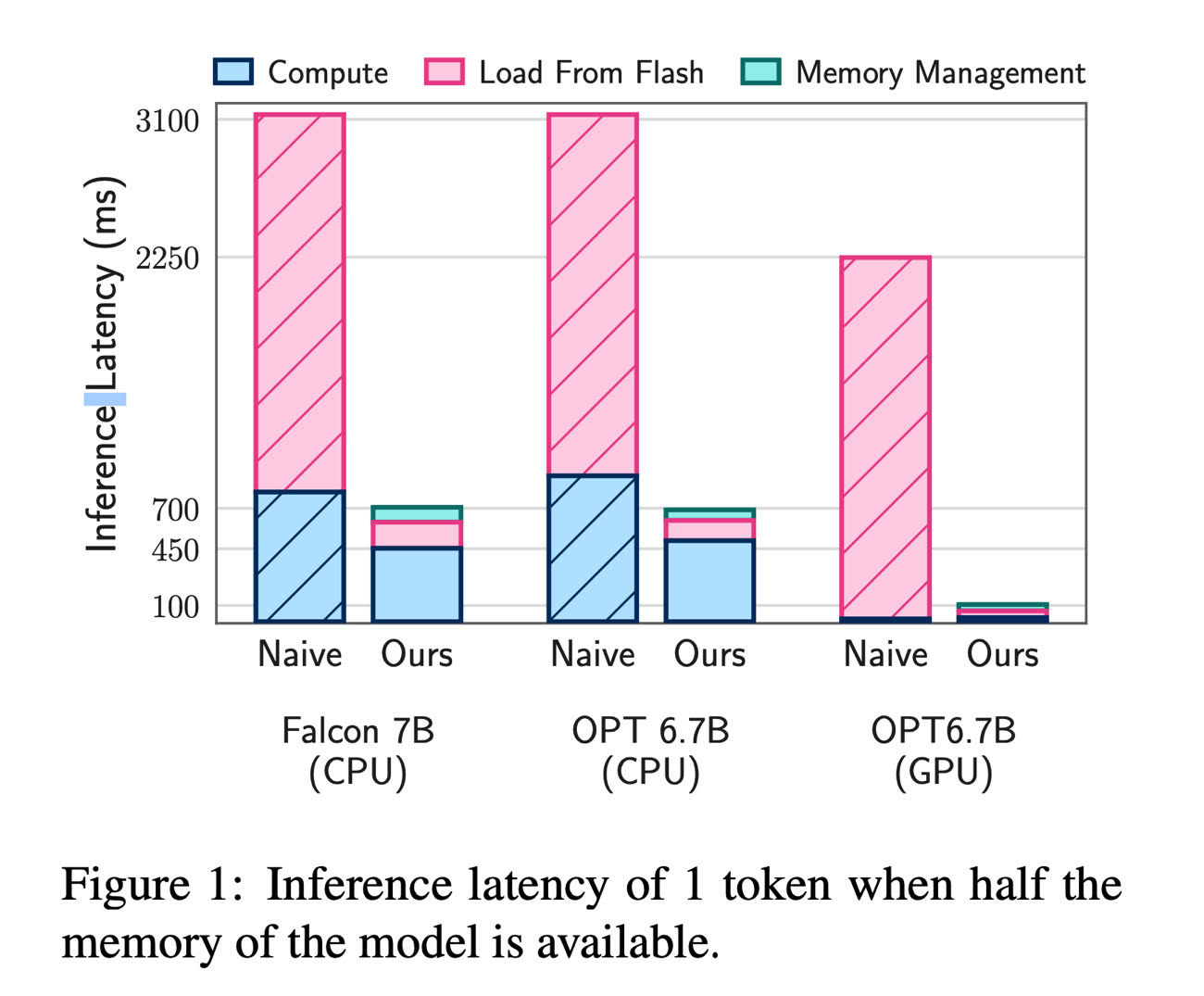
Apple a constaté que cette combinaison de méthodes lui permet d'utiliser des modèles de langage jusqu'à deux fois plus gros que la place disponible en mémoire, avec des vitesses de traitement 4 à 5 fois plus rapides avec le CPU et 20 à 25 fois plus rapides via le GPU.
Si ces travaux devaient déboucher sur une application concrète, Apple pourrait faire marcher ses fonctions d'intelligence artificielle en local plutôt que de recourir à des serveurs. Ce serait plus rapide et plus en phase avec les questions de vie privée.
Le second sujet n'a aucun lien avec le premier, il s'intéresse à la création d'avatars animés réalistes en partant d'un minimum de ressources visuelles. La méthode baptisée HUGS: Human Gaussian Splats utilise entre 50 et 100 images tirées de quelques secondes de vidéo d'un individu en mouvement.
Pas besoin qu'il soit filmé sur un fond uni, le programme va le séparer de l'environnement et, en l'espace de 30 minutes environ, le transformer en un modèle 3D photoréaliste. Il pourra être inséré dans une nouvelle scène et animé comme une marionnette — actuellement à 60 i/s. Apple, qui a collaboré avec l'Institut Max Planck sur ce problème, va prochainement mettre à disposition son code source.





