





La puce A14 des iPhone 12 et la M1 des premiers Mac Apple Silicon disposent d'un nouveau Neural Engine à 16 cœurs capable d’exécuter 11 000 milliards d’opérations à la seconde. En somme, à en croire Apple, une bête de course pour l’apprentissage automatique (machine learning) jusqu'à deux fois plus puissant que la version de l'A12. Ce nouveau moteur dédié aux tâches d'intelligence artificielle tient-il ses promesses ? C'est ce que nous allons voir.
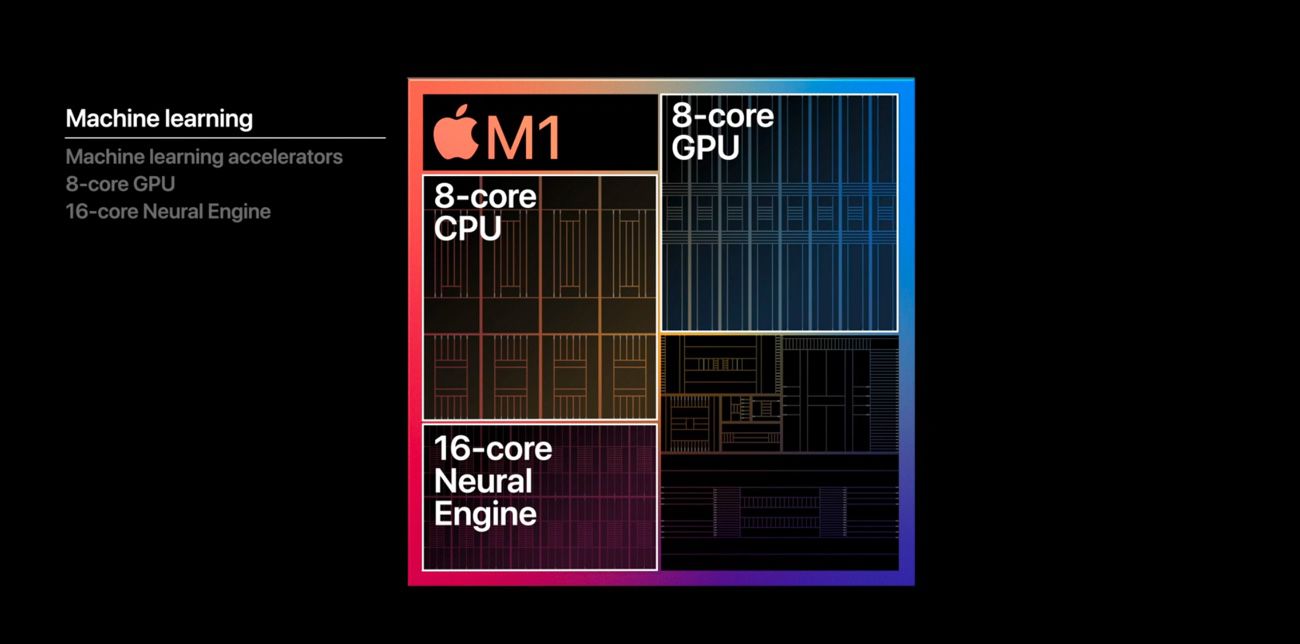
L'apprentissage automatique, comment ça marche ?
L’apprentissage automatique, qui fait partie des domaines de l'intelligence artificielle, est de la prédiction à partir de données. Par exemple, si les données sont issues d’une image, je peux prédire avec un certain niveau de fiabilité que celle-ci représente un chien. Si ces données sont issues d’un tableur, je peux déduire un résultat à partir de paramètres en entrée.
Il y a plusieurs techniques permettant d’effectuer ces prédictions. Ces techniques sont, pour faire simple, des algorithmes paramétrables et les paramètres de ces algorithmes sont des modèles. Et, pour tout cela, il faut un jeu de données de référence en entrée.
Si on reprend l’exemple de la reconnaissance d’un chien dans une photo, je vais donner des millions de photos de chiens à mon …





