





Le Mac Pro a beau être un produit honteusement abandonné par Apple, il reste le Mac le plus puissant actuellement sur le marché dès lors qu’une tâche utilise plusieurs cœurs. Avec son option à 12 cœurs physiques, il aligne 24 cœurs logiques qui peuvent être exploités dans certaines tâches très précises. C’est le cas, notamment, lors de la compilation d’une app. Le code source doit alors être converti en code machine et rassemblé pour former un paquet prêt à être ouvert par un appareil, une tâche lourde qui bénéficie de la puissance d’un Mac Pro.
Du moins, ça c’est la théorie. En pratique, les résultats ne sont pas du tout aussi logiques et c’est même l’inverse qui se produit. C’est ce qu’a remarqué un responsable de LinkedIn quand les développeurs de l’app iOS ont commencé à abandonner leurs Mac Pro à 12 cœurs pour utiliser des MacBook Pro. Interrogés, ils ont répondu que les portables équipés de quatre cœurs seulement étaient plus rapides pour compiler l’app.

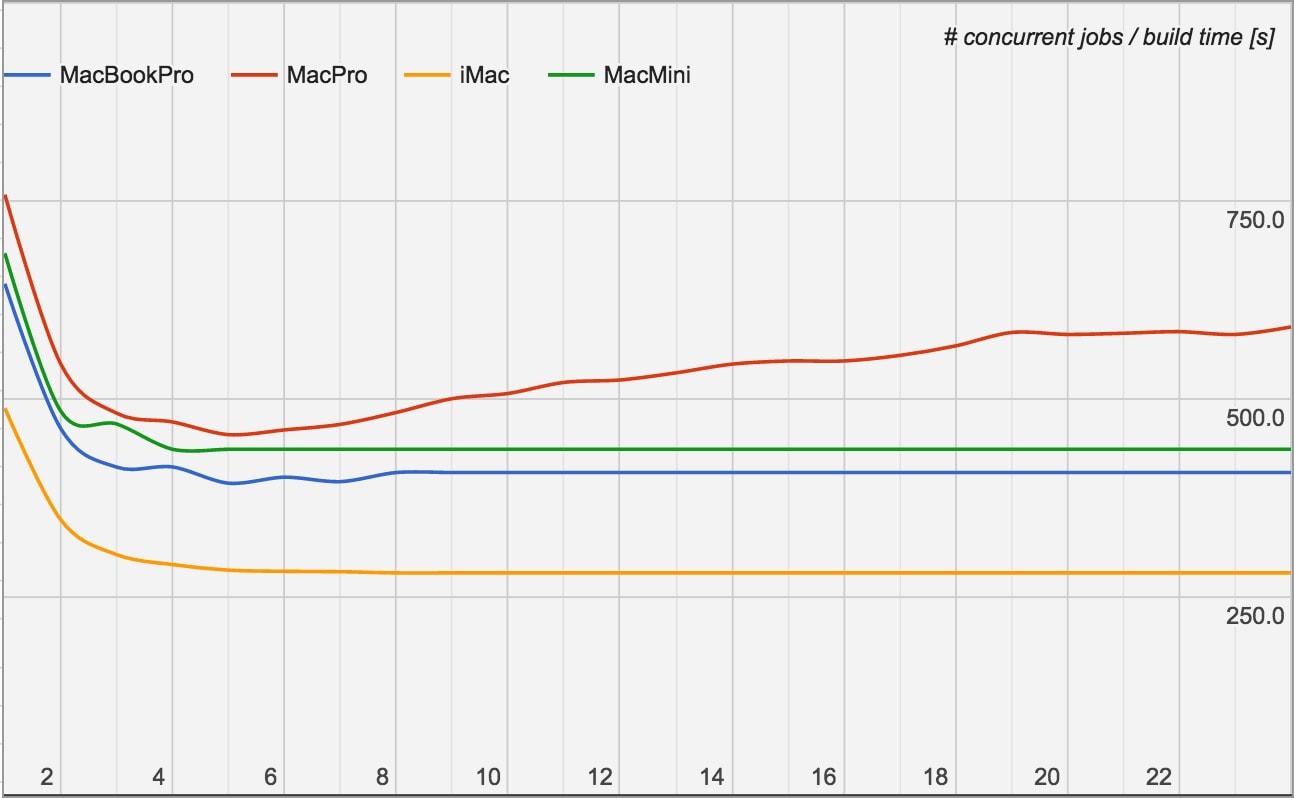
Pour en avoir le cœur net, ce responsable a mené des tests sur tous les Mac qu’il a pu trouver, y compris sur un Mac mini affiché à 1339 € avec l’option Core i7. À titre de comparaison, le Mac Pro avec l’option 12 cœurs est vendu au minimum 8199 €. Sur chaque machine, il a compilé l’app iOS de LinkedIn en utilisant de plus en plus de cœurs et le résultat est étonnant.
Le Mac Pro est effectivement l’ordinateur le plus lent pour mener à bien cette tâche, alors que c’est l’iMac le plus rapide. Ce dernier est un modèle de 2015 équipé d’un processeur Core i7 à quatre cœurs physiques et huit cœurs logiques. Même le Mac mini fait systématiquement mieux que le Mac Pro, dernier du classement quel que soit le nombre de cœurs.
Par défaut, il faut plus de 10 minutes pour que le Mac Pro compile l’app, là où quatre minutes environ suffisent à l’iMac. Un écart énorme qui s’explique a priori par un bug. Xcode peut exploiter autant de cœurs que l’ordinateur peut en fournir, mais contre toute attente, le processus n’est pas accéléré en multipliant les cœurs, il est ralenti.
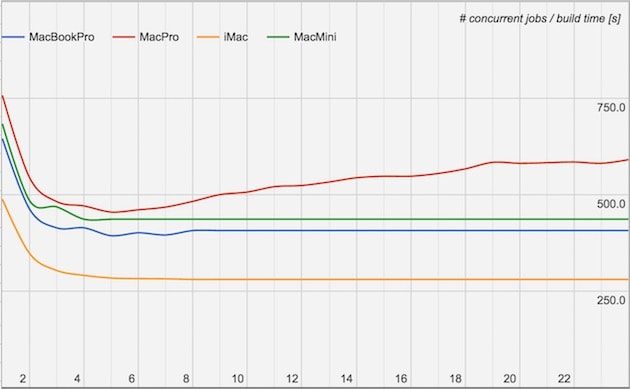
Précisons que ce n’est pas systématiquement le cas et les apps développées uniquement en Objective-C ne souffrent pas du même problème. C’est Swift qui semble être le coupable dans l’histoire et a priori plutôt la troisième version. Notre développeur iOS se plaint également de lenteurs à la compilation depuis le passage à Swift 3 à la fin de l’année.
Suite à cette découverte, ce cadre de LinkedIn a essayé d’isoler le problème en utilisant différentes versions de macOS, en compilant une app beaucoup plus légère et même en testant une compilation avec un système installé sur APFS. Mais rien n’y a fait, il a obtenu systématiquement les mêmes résultats, ce qui l’amène à la conclusion qu’il y a un bug, soit dans macOS, soit dans Xcode.
En attendant un correctif (un rapport de bug a été créé), les développeurs trouveront à la fin de l’article deux solutions temporaires pour améliorer les temps de compilation. Il s’agit déjà de bloquer le nombre de cœurs utilisés par Xcode, sachant que le meilleur étant 5 pour un Mac Pro et 6 à 8 pour les MacBook Pro et iMac à quatre cœurs. Ensuite, désactiver l’indexation Spotlight de certains dossiers diminue également légèrement le temps nécessaire à la compilation.
Apple présentera Swift 4 lors de sa conférence développeurs, au mois de juin. Espérons que ce problème de performances sera réglé avec cette mise à jour qui doit apporter la stabilité, au moins pour le code-source.






{kind=link}
{kind=link}
{kind=link}