





Les experts des séries TV ont bien de la chance : même s'ils vivent à notre époque, ils bénéficient d'une technologie révolutionnaire qui leur permet de transformer une bouillie de pixels en photo propre et nette désignant généralement le coupable ou un témoin très important. Cela donne quelque chose comme ça :
Les prodiges de l'intelligence artificielle permettent néanmoins de nous approcher de plus en plus des résultats obtenus dans les séries et les films de SF. Google Brain, une des expérimentations en intelligence artificielle d'Alphabet, peut ainsi « améliorer » une image très pixellisée de façon assez convaincante. Voici quelques exemples :

Comment ce miracle est-il possible ? S'il est évidemment impossible de créer de la matière à partir de rien, Google Brain exploite deux réseaux neuronaux pour s'approcher de la vérité. Le premier (« conditioning network ») compare les images 8 x 8 avec des photos en haute résolution qu'il réduit à 64 pixels.
Le second réseau (« prior network ») « ajoute » à l'image 8 x 8 des détails en haute résolution, en piochant dans un grand volume d'images HD. Quand l'image source est agrandie, ce réseau y intègre de nouveaux pixels qui correspondent autant que possible à ce que l'image peut représenter. Un exemple : il est probable qu'un pixel marron en haut de l'image soit un sourcil. Quand celle-ci est agrandie, le prior network comble le vide en piochant parmi les sourcils marron de sa collection.
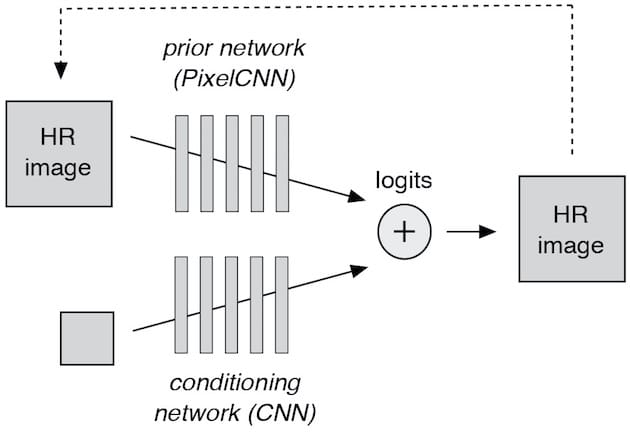
L'image finale est le fruit de la cogitation de ces deux réseaux. Le résultat, c'est une représentation « plausible » de la personne ou de la scène dans la meilleure définition possible, en partant d'une image où les détails sont pratiquement inexistants. Une technique qui donne des rendus parfois étonnants :


Il faut garder à l'esprit que les images en haute résolution ne sont pas réelles. Elles tentent simplement de « deviner » l'image réelle. D'ailleurs, dans le jargon on appelle les détails ajoutés numériquement des « hallucinations ». Les services de police et de justice qui seraient tentés d'appliquer cette technique doivent avoir cette prévention bien en tête : les images créées par Google Brain ne sont que des représentations numériques, et pas la réalité. Pas encore, du moins.
Source :






{kind=link}
{kind=link}
{kind=link}