




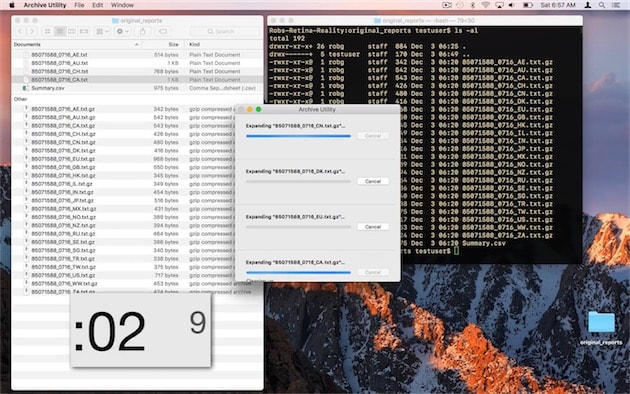
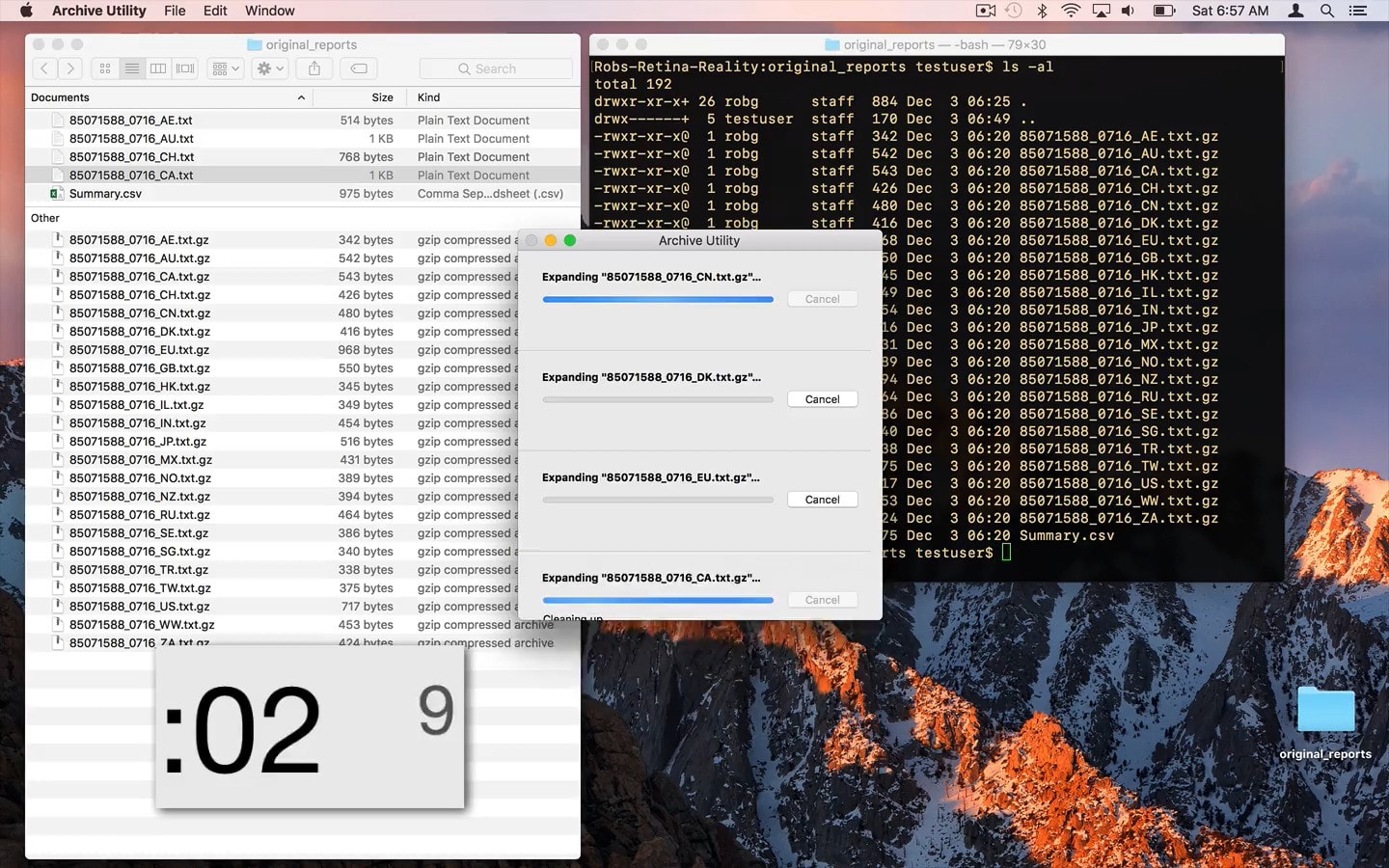
Rob Griffiths est développeur et tous les mois, il récupère 25 rapports de ventes transmis par Apple pour ses logiciels vendus sur le Mac App Store. Ces rapports sont fournis sous une forme archivée (.gz) qu’il faut décompresser pour les exploiter. Précisons que ce sont des fichiers très légers, le plus lourd pèse 1 Ko et en moyenne, ces archives tournent autour de 300 ou 400 octets.
En passant par l’interface de macOS, donc par le Finder et par l’Utilitaire d’archive fourni avec le système, il faut compter environ 13 secondes pour extraire ces données sur son Mac. Même si ce n’est pas grand-chose en soi, c’est extrêmement lent pour décompresser des archives aussi légères. Et d’ailleurs, en passant par le terminal, l’opération sur le même Mac est terminée en 0,013 seconde. Soit environ mille fois plus rapidement, rien que ça !
Comment expliquer une telle différence ? Décompresser des archives aussi légères est une tâche tellement simple qu’elle est quasiment instantanée pour un ordinateur moderne. C’est d’ailleurs le cas avec le terminal : sitôt la commande saisie, l’opération est terminée.
Ce qui ralentit l’opération, c’est en fait l’interface. La vidéo le montre bien, l’utilitaire d’archive de macOS ouvre chaque fichier un par un, il l’affiche dans sa fenêtre, complète la barre de progression, retire l’élément, passe au suivant, etc. Et même s’il traite plusieurs fichiers en parallèle, cela reste une opération progressive où le temps nécessaire pour afficher les données surpasse largement le temps qu’il faut pour décompresser les fichiers à proprement parler.
Le terminal n’a pas à se soucier de l’interface et même s’il traite chaque fichier un par un, il va plus vite qu’en passant par le Finder. Il est si rapide que le gestionnaire de fichiers de macOS n’arrive pas à suivre : si vous regardez attentivement la vidéo, vous verrez que la tâche se termine avant que les fichiers soient affichés dans la fenêtre du Finder à côté.
C’est un cas un petit peu extrême qui pourrait facilement être corrigé si Apple le voulait. Par exemple, l’interface pourrait se contenter d’une seule barre de progression pour gagner du temps. D’autres utilitaires, comme The Unarchiver, s’en sortent d’ailleurs mieux que l’Utilitaire d’archive de macOS. Par ailleurs, la différence n’est aussi spectaculaire que dans ce cas précis, à savoir un grand nombre de petits fichiers compressés.
Si vous êtes dans le même cas que ce développeur que vous voulez gagner un petit peu de temps tous les mois, vous pouvez utiliser la commande de terminal sans passer par le terminal. Automator, Alfred, Keyboard Maestro… les solutions ne manquent pas et vous trouverez des explications à cette adresse.






{kind=link}