Apple M1 Pro/Max : une gestion subtile des cœurs pour un macOS toujours fluide
Un des secrets de la fluidité des Mac Apple Silicon n’est pas seulement à chercher du côté des puces conçues par Apple, macOS joue aussi un rôle déterminant. Le système d’exploitation dédié aux Mac a été mis à jour en même temps que le matériel pour exploiter ce dernier au mieux. Les cœurs économes sont utilisés le plus souvent possible et notamment pour toutes les tâches en arrière-plan, laissant les cœurs puissants disponibles pour les interactions de l’utilisateur.

Comment l’iPhone a appris au Mac à mieux utiliser ses cœurs
Cette répartition des tâches a été revue pour les nouvelles puces plus puissantes présentées le mois dernier par Apple. L’Apple M1 Pro comme l’Apple M1 Max intègrent tous deux un CPU qui peut atteindre dix cœurs avec une organisation différente. Ils ont deux cœurs économes seulement, deux fois moins que l’Apple M1, mais jusqu’à huit cœurs puissants, deux fois plus que la précédente puce.
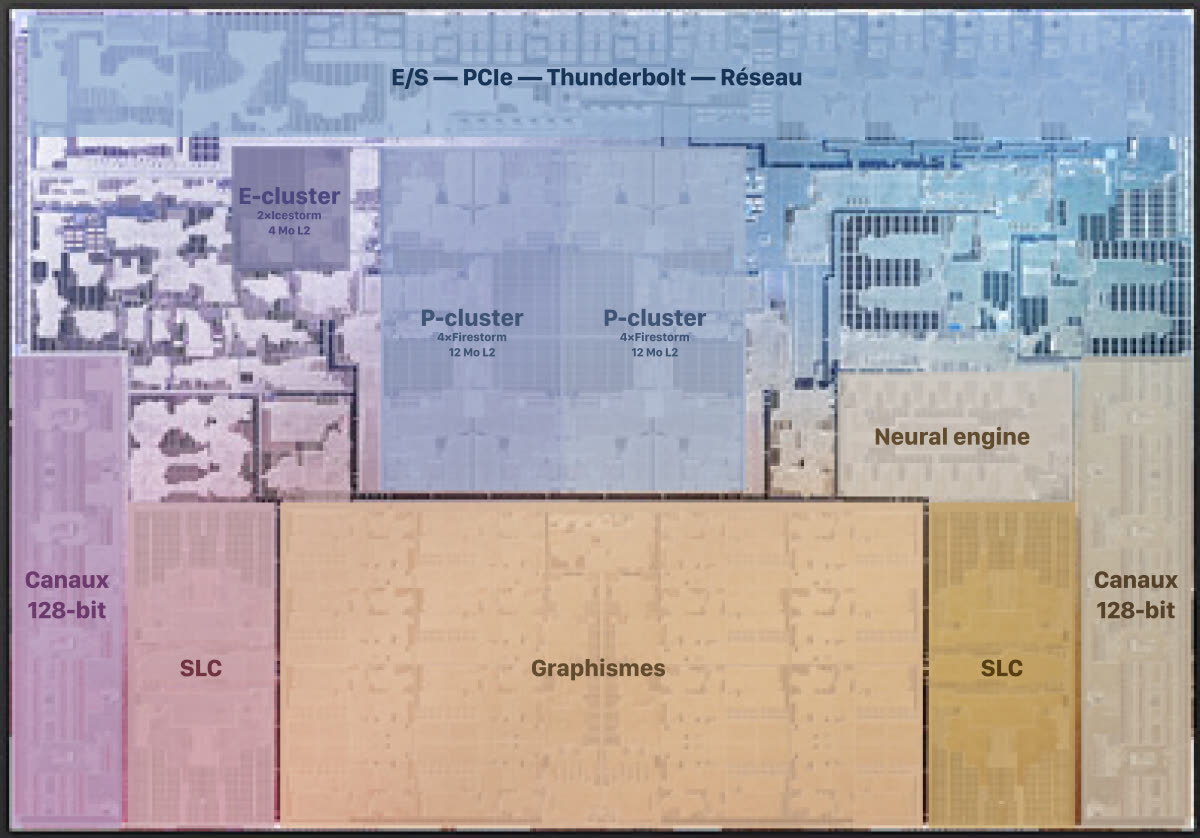
Contrairement à la première puce Apple Silicon, ces nouvelles venues ne disposent pas de suffisamment de cœurs économes pour reposer uniquement sur eux pour la plupart des tâches. De ce fait, le développeur Howard Oakley montre sur son blog que l’organisation est différente et que les cœurs performants sont davantage exploités sur les MacBook Pro. Cela dit, la « qualité de service » qui gère la priorité des tâches a été pensée pour conserver au maximum une fluidité parfaite pour l’utilisateur.
Pour y parvenir, les développeurs de Cupertino reposent sur une hiérarchie à trois niveaux pour les tâches en arrière-plan. Les deux cœurs économes sont utilisés le plus souvent possible, comme sur l’Apple M1. S’ils sont assez puissants pour accomplir la tâche rapidement, ce sont les seuls exploités, mais ils seront en général associés à des cœurs performants. Pas les huit à la fois néanmoins, macOS va se limiter au maximum à quatre cœurs performants et laisser les quatre autres libres. Si la tâche nécessite encore plus de puissance, les quatre derniers cœurs performants peuvent être sollicités, mais ils rendront la main dès que possible.
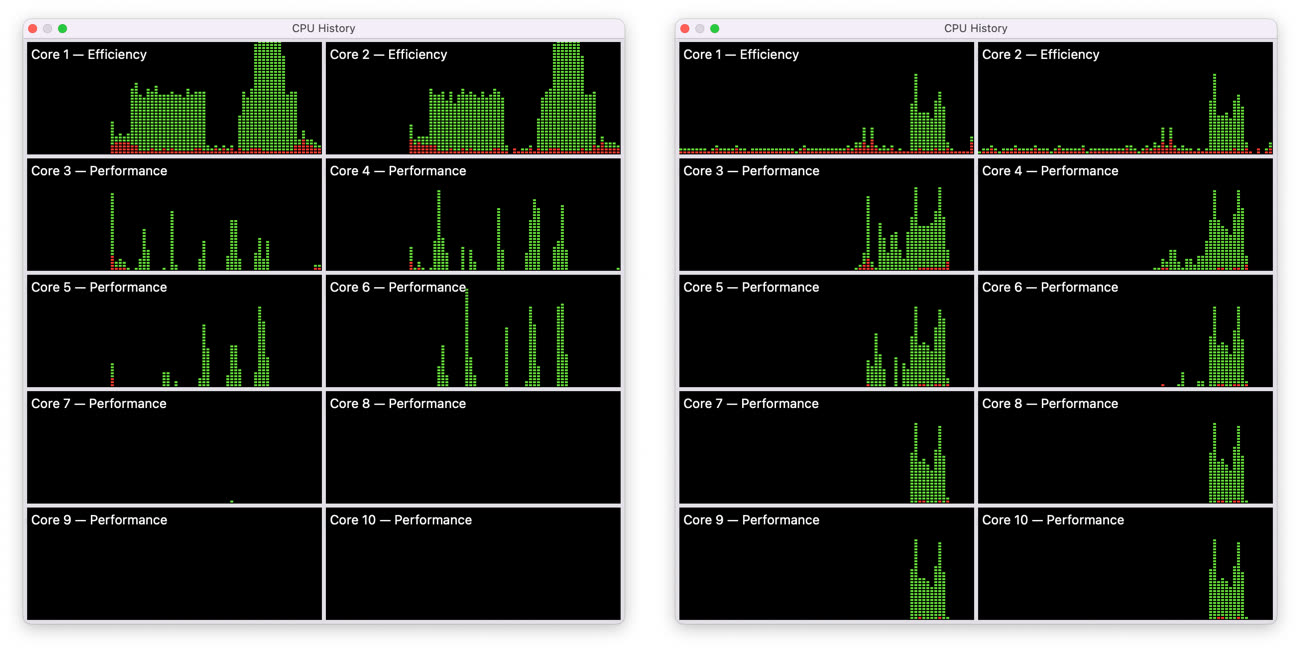
Le développeur conclut ainsi que macOS essaie de garder quatre cœurs puissants libres sous la main en permanence. Tant qu’ils ne sont pas nécessaires, ils restent inutilisés pour les tâches en arrière-plan et peuvent ainsi servir instantanément dès lors que l’utilisateur effectue une action. C’est la clé de l’impression de fluidité à l’utilisation, les MacBook Pro ont presque toujours de la réserve disponible quand l’utilisateur en a besoin. C’est aussi un point essentiel pour limiter la consommation et offrir d’excellentes autonomies à ces ordinateurs portables.
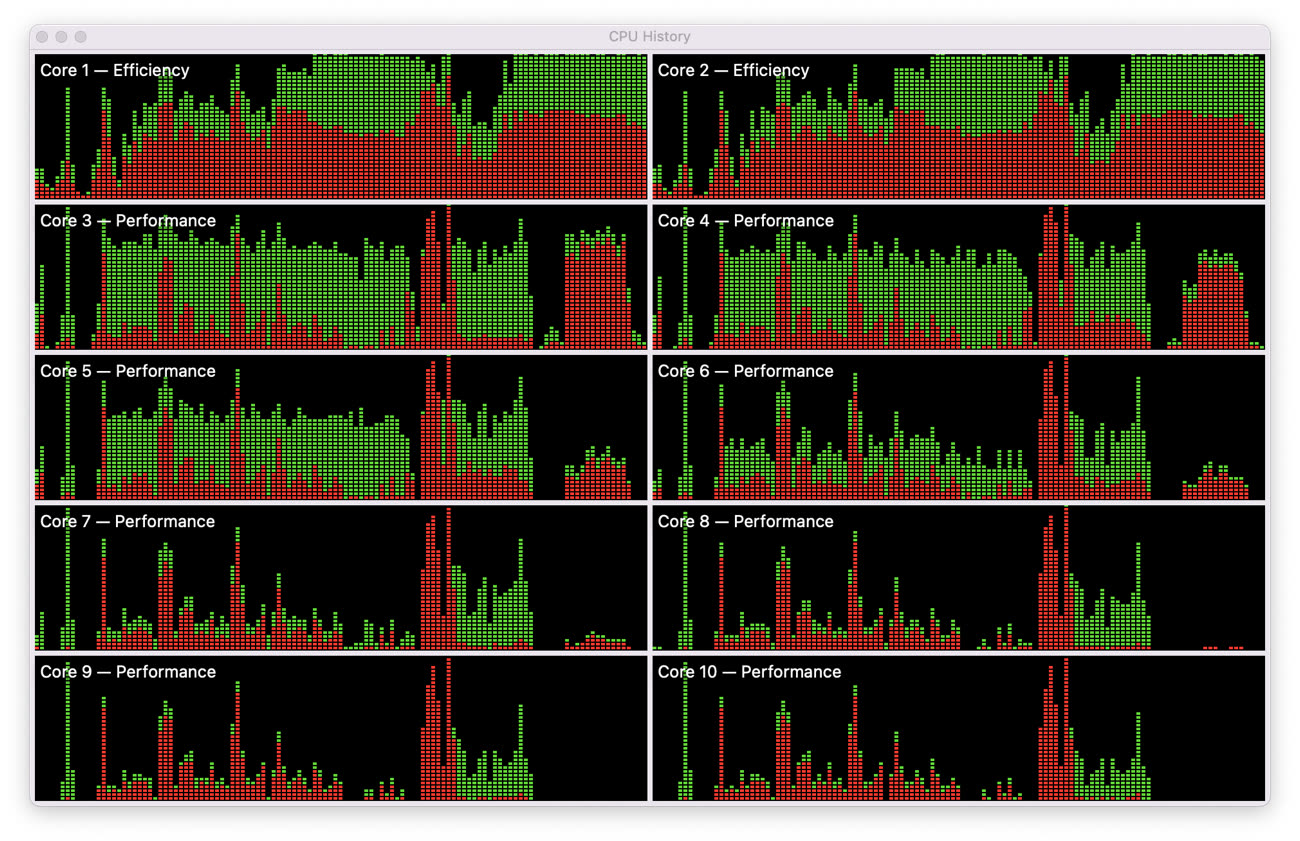
Naturellement, si vous effectuez une opération qui pèse lourd sur le CPU, tous les cœurs seront exploités, cela n’aurait pas de sens de ne pas le faire. Même alors, macOS essaiera de libérer la moitié des cœurs puissants, comme le montre cet exemple enregistré pendant une tâche exigeante pour le processeur. Les cœurs 7 à 10 sont en moyenne moins utilisés et ce n’est que lorsque les six autres cœurs ne suffisent plus qu’ils entrent en action.
Pourquoi laisser quatre cœurs performants aussi libres que possible ? Ce chiffre n’a pas été choisi au hasard, il se comprend en analysant de plus près la puce conçue par Apple et en notant que les huit cœurs performants sont regroupés en deux blocs de quatre, on parle de « clusters ». C’est pour cette raison que macOS n’en utilise que quatre : sous le capot, le système privilégie un cluster et laisse le deuxième aussi peu exploité que possible.

Test des MacBook Pro 2021 : des Mac Pro portables









@fte
"mais bien ma conviction - essentiellement rationnelle - qu’il n’y a absolument rien de révolutionnaire dans la proposition actuelle d’Apple pour le grand public."
Le terme « révolutionnaire » est évidemment fort.
Par contre et contrairement à toi je reste persuadé que les cibles du Mac sont très sensible au conséquent gain de confort d’usage qu’offre les nouvelles machines et que la transition ARM fait évoluer positivement l’attractivité du Mac.
Attendons un peu pour voir ce que cela donnera en évolution de PDM pour se faire une religion définitive 👀
@fte
"Même le geek en moi a du mal à trouver le machin révolutionnaire."
Je n’ai strictement jamais parlé de « révolution » 😎
Une tâche lourde avec des cœurs au repos 😂😂😂
Depuis quelle génération de Mac y’a-t’il ses cœurs économes ?
J’aimerai bien savoir si mon MacBook 12 Retina de 2015 en a.
Quant à mon MacBook Pro 2011 core2duo….
@ BingoBob
Il me semble qu'on perle de cœurs "économes" surtout depuis que Apple produit ses propres puces et surtout depuis les M1.
Côté Intel, je ne sais pas pour leurs processeurs récents, mais c'est sûr que le concept n'existe pas pour les vénérables C2D. Ceci dit, je doute aussi pour les i5 et i7, mais il y a tellement de déclinaisons/générations de i7...
@BingoBob
Cela ne concerne que les Mac Apple Silicon, aucun Mac Intel.
@BingoBob
que les Macs avec processeurs Apple arm (les "apple silicons" comme le M1 et successeurs)
@BingoBob
En fait, ARM (porté par son cœur de cible des 10 dernières années) a beaucoup fait pour réduire la consommation de ses designs et ainsi augmenter l’autonomie…
Le principe big.Little a permis aux téléphones de ne consommer beaucoup que quand l’utilisateur tire dessus et de rester (très) sobre pour les petites taches de fond.
En gros un cœur qui a de la patate, même si tu réduit sa fréquence pour ne lui donner que des taches légères, consommera toujours beaucoup plus qu’un cœur fait pour rester sobre (tu peux pas avoir le beurre et l’argent du beurre)!
Intel n’a Jamais cherché à optimiser sa consommation à ce point… les OS sous Intel utilise historiquement une stratégie d’allocation symétrique des resources (chaque cœur se vaut) même si dans le détail c’est pas complètement vrai… (ex: l’hyper threading ne double pas réellement les perf, ou encore, pour des questions de cache propre à chaque processeur, un dual socket n’est pas équivalent à un CPU avec deux fois plus de cœurs)
Bref: on peut très bien observer des « battements » sur un CPU Intel ou une tache bascule d’un cœur à un autre avant de revenir (histoire d’homogénéiser la production de chaleur sur toute la surface du CPU, MAIS rien de comparable avec cette gestion asymétrique de « si tu ne demande pas beaucoup de ressources, je te mets là, mais dès que tu as besoin de la cavalerie, je te bascule de l’autre côté… et tu vas voir ce que tu vas voir!!! »
Donc non, il n’y a rien de comparable chez Intel (sauf dans la dernière génération avec des mécanismes qui attendent encore l’optimisation côté OS ), et donc oui, on parle bien de choses spécifiques aux M1… (du moins dans le monde PC… car ça fait 10 ans que iOS et Androïd utilisent ça avec toutes les générations de puces qui correspondent !!! Je veux pas dire de bêtises, mais Apple a toujours fait du big.Little … depuis l’A4! Intel a donc un sacré retard à rattraper!)
@fendtc
"Je veux pas dire de bêtises, mais Apple a toujours fait du big.Little … depuis l’A4! Intel a donc un sacré retard à rattraper!)"
Ce ne sont pas des bêtises strictement. Mais de grossières simplifications voire caricatures, absolument.
arm fait du big.little. Pas Apple. Apple utilise les designs d’arm et les personnalise.
Intel a des coeurs puissants et des coeurs économes dans son catalogue depuis avant l’iPhone.
La génération Alder Lake n’a pas été développée à la va-vite depuis la semaine dernière. Intel a des prototypes dans ses labos depuis des années. Et du bug.little depuis peut-être plus d’une décennie. Mais sans raison commerciale valable d’en commercialiser jusqu’à 2020+.
Intel a par contre accumulé les problèmes sur son process de gravure. C’est ce point qui les a ralenti techniquement ces dernières années.
Alder Lake est définitivement au point. Avec des choix différents des M1 cependant.
Bref. Il ne faut ni sous-estimer Intel, ni sur-estimer Apple. Ils sont tous deux excellents dans leurs domaines respectifs.
Je suis en outre très curieux de ce qu’Intel aura appris de ses déboires sur leur process de gravure. Il n’y a rien de tel que se manger un bon gros mur pour découvrir et inventer de nouvelles choses, de rectifier des babioles qui auraient été ignorées autrement, etc.
@ fte : « Intel a des prototypes dans ses labos depuis des années. Et du bug.little depuis peut-être plus d’une décennie. »
Un lapsus révélateur ? 😁
@BeePotato
"Un lapsus révélateur ? 😁"
Pour le coup c’est bien possible. 😂
@fendtc
Merci pour ta réponse hyper précise.
Je comprends mieux maintenant pourquoi sur mon MacBook Retina, Time Machine qui se lance toujours quand je travaille…, fait chauffer l’ordinateur. Alors que je ne fais que du traitement de texte !
@fendtc
« Apple a toujours fait du big.Little … depuis l’A4! Intel a donc un sacré retard à rattraper!) »
Apparement c’est plutôt depuis l’A10 de l’iPhone 7 😊
https://www.igen.fr/tests/2016/09/test-de-liphone-7-97268
@BingoBob
En tout cas, déjà l’A10 fait référence à cette architecture big.Little avec 2 cœurs de chaque…
https://en.wikipedia.org/wiki/Apple_A10
@Nicolas.
Est ce que le mode Eco de Monterey coupe les coeurs puissant des puces M1 pour ne les faire tourner QUE sur les coeurs économes ou pas du tout? 😊
La question est aussi de savoir quels logiciels tirent parti de la configuration des M1 Pro et M1 Max et ne sont pas bridés par le fait de leur développement multiplateforme.
@ Mac1978
À vu de nez, comme ça au hasard 😉, je dirais Logic Pro ou Final Cut Pro qui sont proposés en option quand on achète un MacBook Pro.
@Mac1978
> La question est aussi de savoir quels logiciels tirent parti de la configuration des M1 Pro
> et M1 Max et ne sont pas bridés par le fait de leur développement multiplateforme.
Ce n'est pas parce que le code d'une app est multiplateforme qu'il n'est pas multithreadé.
Hors on parle précisémment ici de la capacité du schéduleur du noyau de macOS a distribuer chaque thread sur des coeurs économes ou performants en fonction de l'intensité de leur activité.
La plus value ici est apportée par le scheduleur qui sait gérer des types de coeurs hétérogènes, et il n'a nul besoin de l'aide active des développeurs tiers pour cela. Au pire, cela repose sur la priorité demandée du thread, un mécanisme qui est parfaitement disponible y compris si l'on utilise du code portable pour le faire (genre pthread_setschedparam, au hasard).
Par ailleurs un bon scheduleur d'OS est parfaitement capable de savoir si un thread se tourne les pousses ou si au contraire il tourne à fond et appliquer une politique en conséquence.
Ce n'est pas la même chose quand il s'agit, pour bénéficier d'un gain particulier apportée par du matériel propriétaire, de devoir faire explicitement appel à une API disponible uniquement sur une plateforme particulière. Là, oui.
Mais le multithreading, la notion de priorité d'exécution, on le trouve dans toutes les plateformes logicielles récentes.
Les logiciels qui ne bénéficieront pas, donc, ce sont surtout qui ne sont pas multithreadés. Code natif ou pas.
@ byte_order
> Les logiciels qui ne bénéficieront pas, donc, ce sont surtout qui ne sont pas multithreadés. Code natif ou pas.
100% d'accord.
Malheureusement je crains que nombre de développeurs ne maîtrisent pas ce sujet autant qu'ils le devraient.
@marc_os
Je pense que le sujet est assez complexe car il
n’y a que certains types de processing quo se prêtent le mieux à ce genre de multi-thread.
Car si c’est pour investir du temps pour un gain minime, sans parler de la maintenance.
Cependant pour l’implémenter il faut que l’archietcture de l’app soit conçur des le départ pour cette stratégie.
@marc_os
"Malheureusement je crains que nombre de développeurs ne maîtrisent pas ce sujet autant qu'ils le devraient."
Pas aussi simple.
- Une application doit idéalement être architecturée dés l’origine sur une approche multi thread. Appliquer cette approche sur une base de code existante conséquente à posteriori est une gageure.
- Le development en multi thread est par nature plus complexe à effectuer
- Transformer l’existant est complexe, long et coûteux.
- Dans bien des cas sur de l’héritage on ne cible que certaines fonctionnalités pour les porter en version //
- Les gains de performance consequents,au delà de la réactivité générale, ne peuvent advenir que sur des classes d’algorithmes pouvant être parallèlisés avec un bénéfice. Ce qui ne représente qu’une part des traitements
- Les grands bénéfice sur des usages relativement communs sont sur le traitement et la génération d’images, le traitement et la génération de vidéo, le traitement de signal de façon plus général…
- Danse bien des cas ces algorithmes tirent encore un plus grand bénéfice du parallélisme massif des approches GPPU.
…
Au final la démultiplication des cœurs au delà d’un seuil raisonnable ne bénéficie qu’aux usages “digital media creation” en dehors de niches de calcul et de simulation scientifiques et/ou technique.
Mais est-ce réellement un pb ? Les niveaux de performance et de réactivité atteint sur les machines d’entrée de gamme répondent largement aux usages ne pouvant être parallèlisés sur une grande majorité de cas.
@YetOneOtherGit
"- Le development en multi thread est par nature plus complexe à effectuer"
Programmation fonctionnelle. Ça résout tellement de difficultés…
@fte
"Programmation fonctionnelle. Ça résout tellement de difficultés…"
Tu prêches un convaincu de longue date du fonctionnel 😉
Après malgré le remarquable retour en force de se paradigme je ne cois pas advenir d’application majeure sur ordinateur individuel reposant sur lui dans un avenir proche 😎
@YetOneOtherGit
"Au final la démultiplication des cœurs au delà d’un seuil raisonnable ne bénéficie qu’aux usages “digital media creation” en dehors de niches de calcul et de simulation scientifiques et/ou technique."
Pas qu’aux.
Et que diable peut bien signifier "seuil raisonnable" ?!
Les OS de notre époque tournent facilement 50 ou 100 processes de base pour l’ensemble des fonctionnalités de l’OS. À chaque process - évidemment mais plupart multithreadés - son cœur et la réactivité sera sympa. 100 coeurs ? C’est raisonnable ? Ça me semble raisonnable. Je valide.
@fte
"Et que diable peut bien signifier "seuil raisonnable" ?!"
C’est effectivement flou? mais difficile de définir un seuil absolu.
6/8 coeur me,semble représenter un seuil raisonnable 😉
@fte
"Les OS de notre époque tournent facilement 50 ou 100 processes de base pour l’ensemble des fonctionnalités de l’OS. "
Tu sais bien que ces process sont souvent fort peu consommateurs de ressources 😎
Au passage même sur la part serveur l’essor des approches VM repose justement sur le fait que cette mutilation des ressources d’une machine sur plusieurs instances d’OS est le plus efficace moyen de maximiser l’usage du potentiel de la machine.
Sur un poste client rare sont les usages largement partagé qui peuvent et pourront tirer d’une multiplication des cœurs au delà des offres standards actuelles 😉
@ 0MiguelAnge0
Apple a introduit Grand Central Dispatch (libdispatch) avec Mac OS X 10.6 et iOS 4, facilitant grandement la gestion du multithread en général, et permettant dans sa plus simple expression de découpler le code de gestion de l'interface des traitements. Par exemple gérer facilement le traitement d'un téléchargement qui prend du temps dans une tâche indépendante tournant en "parallèle" avec le reste.
Ça fait un bail quand même.
De plus, GCD n'est qu'une aide, un moyen de faire facilement ce qui peut être fait depuis toujours dans le monde Unix à la base de macOS;
J'aurai pensé que dès lors que les 4 derniers cores sont solicités, les 2 basses performances soient uniquement utilisés pour la réactivité de l'OS et des taches secondaires.
- 2
- 2 + 4
- 4 + 4
- 4 + 4 + 2
@fte
Il est clair qu'Intel a sorti quelque chose en apparence chouette avec Alder Lake, avec enfin du neuf. Mais on manque encore un peu de recul. L'élément un peu inquiétant, c'est la consommation. On peut presque faire un parallèle avec Nvidia pour le passage de leur série RTX 20x0 à 30x0 : des gains spectaculaires, en augmentant fortement le TDP.
En s'autorisant à monter à 241W, les gars de chez Intel ont possiblement calculé leur coup pour être compétitif face à AMD. J'imagine aussi fort bien que cette sortie a été un peu précipitée pour couper l'herbe en anticipation des Zen 4 (rumeurs de +25% en IPC et +40% en global...? on imagine sans peine quelques watts en plus sur la table aussi... AMD a de la marge avec son TDP actuel à 105w en gamme Desktop...). Intel a énormément progressé, mais je ne serais pas étonné que les Zen 4 soient très compétitifs... la fenêtre de sortie pour Intel était donc très très courte pour s'attirer les faveurs de la presse, et on comprend bien qu'il fallait sortir au plus vite même à gamme incomplète... sous peine d'éclipser leurs progrès...
Côté Apple, je dois avouer que je redoutais ces M1 Pro/Max depuis les rumeurs annonçant une configuration à 8+2. Vu le nombre de transistors occupés par les cores efficiency, manquait-on à ce point de place pour ne pas pouvoir proposer un 8+4 cores ? Bon, apparemment il y a quelques améliorations sur les core efficiency (je n'ai pas trouvé d'infos si c'est un réellement changement ou simplement le cache plus élevé), donc cela mitige un peu le problème, mais il est manifeste que l'impression d'immense fluidité lorsque l'on bosse sur un M1 vient de ces 4 cores efficiency qui absorbent toutes les tâches de fond utiles ou inutiles que l'on se traine sur un ordinateur. Quand on voit comme les Onedrive, Slack, Teams, CreativeCloud, etc... bouffent du CPU en arrière plan, on est bien content de pouvoir les parquer dans des cores efficaces.
Moi qui rêve de trouver un jour un successeur au macbook 12 avec moins de 1 kg sur la balance, je verrais bien la machine avec un 2+8 cores. Ah, tiens, c'est ce qu'annonce Intel pour les ultraportables (mais avec une conso bien plus élevée qu'un M1 donc intérêt limité sans doute...)
Cela étant dit je suspecte Apple d'avoir fait le service minimum niveau CPU. Peut-être parce que l'architecture globale du M1 ne pouvait pas supporter mieux que 10 cores (limites d'interconnections ou autres... le M1 étant manifestement un peu limité déjà au niveau des lignes PCIe, et apparemment maintenant au niveau bus mémoire CPU pour les M1 Pro/Max), et donc Apple a cherché le meilleur compromis pour faire avec ce qu'ils avaient "en attendant".
Ou peut-être qu'ils ont calibré un processeur "compétitif" à un instant T tout en se ménageant mieux pour inciter à un renouvellement régulier, et se préserver une belle roadmap sur quelques années, un peu comme Intel distillait ses augmentations de coeurs petit à petit pour justifier des MAJ chaque année...
Perso, pour un usage desktop, je n'ai a priori pas l'utilité du GPU d'un M1 Max. Par contre, l'espace mangé par cet énorme GPU aurait pu servir en partie pour doubler le nombre de cores (même plus quand on voit les photos...). Le must (ou nécessité ?) serait en plus d'avoir une sorte de turbo sur un core lorsque tous les cores high performance ne sont pas sollicités (Intel jouait avec cela, la fréquence baissant avec le nombre de cores actifs), afin d'avoir une réactivité maximale pour les tâches du quotidien... et de la réserve pour les usages lourds type compilation, compression, ou autre. Car augmenter les cores pour augmenter les cores, ce n'est pas la panacée non plus. Je ne sais pas dans quelle mesure ils en ont sous le pied pour améliorer les perf single-thread au delà de jouer sur la fréquence, mais un maxi-core pensé desktop pour une config 1+8+8, ça aurait du sens aussi pour du confort au quotidien. Sans doute pas le plus efficace en rapport perf bench/watt, mais utile au quotidien pour ce glouton de MacOS et ces gloutons d'applications modernes...
M2, M3, M4...
Je suis surpris de voir qu’une information importante de l’article mentionné en référence n’a pas été plus reprise que cela :
Les 2 cœurs efficients sont d’après ses mesures plus performants lorsque le MacBook Pro est connecté à une prise que lorsqu’il est uniquement sur batterie.
Et cela ne concerne que les cœurs efficients.
Ça ne s’applique pas aux cœurs performants.
https://eclecticlight.co/2021/11/04/m1-pro-first-impressions-2-core-management-and-cpu-performance/
« Differences in performance were much greater on the E cores, where they also varied according to whether the MBP was running on battery alone:
M1 0.409 s (100%)
M1 Pro on battery 0.340 s (83%)
M1 Pro on mains 0.169 s (41%) »
« The end result is that the two E cores in the M1 Pro/Max are significantly faster (in some respects, at least) than the four E cores in the M1, although the E (but not the P) cores are slowed when running on battery alone. »
Pages