Le CTO d'AMD prépare l'après multicore
Comme la course au gigahertz a pris fin, la course au multicore s'arrêtera bien aussi un jour. C'est du moins ce qu'a déclaré de directeur technique d'AMD pour les serveurs, Donald Newell. « La guerre du nombre de cores viendra un jour à finir. Je ne mettrai pas de date précise là-dessus, mais je ne compte pas moi-même voir 128 cores sur une matrice de serveur grand format d'ici la fin de la décennie. »
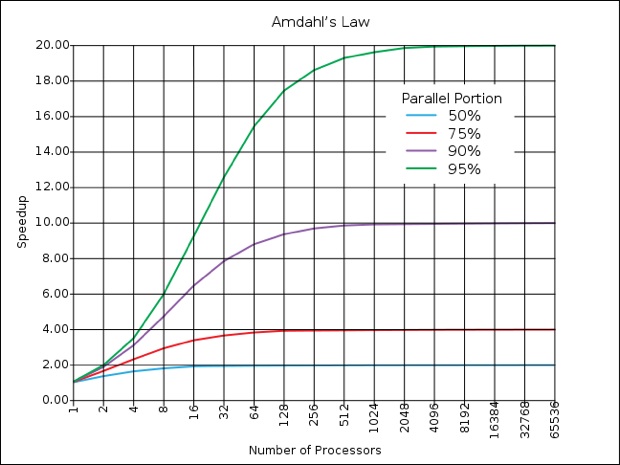
Et pour cause, selon la loi d'Amdahl, la portion parallèle des logiciels doit être de 75 % pour qu'une différence se fasse sentir avec 128 processeurs, le tout pour n'obtenir au mieux qu'une accélération par quatre (lire Le monde parallèle de Photoshop)
Les serveurs ont toutefois la tâche plus facile pour tirer parti des processeurs multiples, dans la mesure où chaque requête d'un poste client est susceptible de lancer une tâche du côté serveur, alors que les machines mono-utilisateurs doivent morceler les tâches pour obtenir un effet de calcul parallèle.
« Ça n'est pas irréaliste pour une feuille de route technologique, mais ça l'est pour une feuille de route d'usage, les contraintes en termes d'énergie auxquelles sont tenus les serveurs ne rendraient pas faisables des puces avec autant de cores. »
Le cadre d'AMD estime qu'Intel prendra la même direction. Sachant que celui-ci a passé 16 ans chez Intel avant de rejoindre AMD l'été dernier, il a sans doute de bonnes raisons de le penser. De quoi soulager quelque peu les développeurs sur lesquels toute la pression de l'accélération matérielle s'est focalisée, afin que leurs logiciels tirent le meilleur parti possible de ces multiples processeurs.
« Nous pensions que nous construirions un jour un processeur à 10 GHz », se souvient Newell, de l'époque où il travaillait chez Intel. « Ça n'est que lorsque nous nous sommes rendus compte qu'ils seraient si chauds qu'ils pourraient fondre la croûte terrestre, que nous avons préféré ne pas le faire. », plaisante-t-il.
L'après multicore, selon lui, consistera à équiper les processeurs de circuits dédiés au lieu de multiplier les processeurs génériques. Ce qui les fera ressembler à des systèmes-sur-une-puce (SoC), avec des sections dédiées à des tâches particulières, comme l'encryptage, le rendu vidéo, ou la gestion du réseau. « Il n'y a rien qui nous empêche d'ajouter des fonctionnalités précises sur une matrice afin de permettre des calculs plus efficaces. Vous devez vous attendre à l'émergence d'architectures hétérogènes, là où nous identifierons des fonctions qui sont largement utiles mais qui ne se retrouvent pas nécessairement dans une instruction que vous souhaiteriez ajouter à l'architecture x86. » De fait, ces unités fonctionneraient comme des co-processeurs. « Nous développons actuellement un jeu de techniques architecturales pour rendre cette intégration bien plus facile. »
AMD comme Intel ont commencé à poser des jalons dans ce sens, avec des produits qui mélangeront CPU et GPU sur une seule et même matrice. La gestion de l'énergie est un autre champ d'exploration : « Il fut un temps où ça n'était qu'une pensée après coup. Jusqu'en 2004, la valeur ne tenait qu'aux performances. » Mais rapidement les besoins en énergie des serveurs sont devenus préoccupants et les fabricants de processeurs ont pris en compte ce besoin dans leurs designs, des éléments qui ont également été mis à profit notamment pour les ordinateurs portables qui ont besoin de plus de puissance tout en consommant moins d'énergie.
Reste que le département marketing des fabricants aura quelque difficulté à faire briller leurs produits dans les diverses comparaisons : s'il était facile de comparer les cycles d'horloges ou le nombre de cores (pour toutes inappropriées que ces comparaisons aient pu être par ailleurs, entre processeurs RISC et CISC par exemple), la gestion de tâches dédiées sera plus délicate à évaluer de façon numérique
Et pour cause, selon la loi d'Amdahl, la portion parallèle des logiciels doit être de 75 % pour qu'une différence se fasse sentir avec 128 processeurs, le tout pour n'obtenir au mieux qu'une accélération par quatre (lire Le monde parallèle de Photoshop)
Les serveurs ont toutefois la tâche plus facile pour tirer parti des processeurs multiples, dans la mesure où chaque requête d'un poste client est susceptible de lancer une tâche du côté serveur, alors que les machines mono-utilisateurs doivent morceler les tâches pour obtenir un effet de calcul parallèle.
« Ça n'est pas irréaliste pour une feuille de route technologique, mais ça l'est pour une feuille de route d'usage, les contraintes en termes d'énergie auxquelles sont tenus les serveurs ne rendraient pas faisables des puces avec autant de cores. »
Le cadre d'AMD estime qu'Intel prendra la même direction. Sachant que celui-ci a passé 16 ans chez Intel avant de rejoindre AMD l'été dernier, il a sans doute de bonnes raisons de le penser. De quoi soulager quelque peu les développeurs sur lesquels toute la pression de l'accélération matérielle s'est focalisée, afin que leurs logiciels tirent le meilleur parti possible de ces multiples processeurs.
« Nous pensions que nous construirions un jour un processeur à 10 GHz », se souvient Newell, de l'époque où il travaillait chez Intel. « Ça n'est que lorsque nous nous sommes rendus compte qu'ils seraient si chauds qu'ils pourraient fondre la croûte terrestre, que nous avons préféré ne pas le faire. », plaisante-t-il.
L'après multicore, selon lui, consistera à équiper les processeurs de circuits dédiés au lieu de multiplier les processeurs génériques. Ce qui les fera ressembler à des systèmes-sur-une-puce (SoC), avec des sections dédiées à des tâches particulières, comme l'encryptage, le rendu vidéo, ou la gestion du réseau. « Il n'y a rien qui nous empêche d'ajouter des fonctionnalités précises sur une matrice afin de permettre des calculs plus efficaces. Vous devez vous attendre à l'émergence d'architectures hétérogènes, là où nous identifierons des fonctions qui sont largement utiles mais qui ne se retrouvent pas nécessairement dans une instruction que vous souhaiteriez ajouter à l'architecture x86. » De fait, ces unités fonctionneraient comme des co-processeurs. « Nous développons actuellement un jeu de techniques architecturales pour rendre cette intégration bien plus facile. »
AMD comme Intel ont commencé à poser des jalons dans ce sens, avec des produits qui mélangeront CPU et GPU sur une seule et même matrice. La gestion de l'énergie est un autre champ d'exploration : « Il fut un temps où ça n'était qu'une pensée après coup. Jusqu'en 2004, la valeur ne tenait qu'aux performances. » Mais rapidement les besoins en énergie des serveurs sont devenus préoccupants et les fabricants de processeurs ont pris en compte ce besoin dans leurs designs, des éléments qui ont également été mis à profit notamment pour les ordinateurs portables qui ont besoin de plus de puissance tout en consommant moins d'énergie.
Reste que le département marketing des fabricants aura quelque difficulté à faire briller leurs produits dans les diverses comparaisons : s'il était facile de comparer les cycles d'horloges ou le nombre de cores (pour toutes inappropriées que ces comparaisons aient pu être par ailleurs, entre processeurs RISC et CISC par exemple), la gestion de tâches dédiées sera plus délicate à évaluer de façon numérique








Je rejoint ce monsieur sur la spécialisation
je me souviens d'une expérience qui consistait à faire un simple PC avec des Proc les plus basique. Mais en redéfinissant l'architecture non plus comme un machine avec un bus mais comme des sous systèmes communicants.
imaginez une unité de traitement qui ne connait que sa mémoire et un interface réseau
d'un autre côté une unité d'interaction qui ne connait que clavier souris et écran
un autre que réseau, une autre que disque etc.
le tout relier par un réseau interne haut débit c'est ce qui à été fait avec de bêtes processeurs à 25Mhz dans cette expé.
bien sur le coût rendait la fabrication d'une telle machine rédhibitoire. mes les perspectives d'évolution vers des performance accrue semblaient prometteuse.
ça n'a pas quitté les labo car dans les année 80-90 c'est la course au MHz (oui méga à l'époque) qui primait et qui donnaient à moindre coût d'aussi bonne perspectives.
certain de ces concepts sont entrés dans l'électronique de nos machines.
on maitrise beaucoup mieux les réseau aujourd'hui et banaliser les échange dans la machine en supprimant la centralisation sur le processeur permet d'envisager des chose comme un lecteur enregistreur de DVD qui embarque son propre décodeur H.264 qui envoie l'image au sous système qui gère l'écran et le son à l' audio sans intervenir sur le processeur.
bref ce n'est pas une approche nouvelle mais jusqu'à maintenant chaque fois qu'une avancé c'est faite dans le domaine les machine "Généraliste" ont montrée qu'elle faisaient aussi bien. je pense par exemple au processeurs LISP
(LISP est un langage utilisé en IA entre autre) Le noyau d'interprétation est petit et peut très bien être câble dans un processeur. on obtient donc une machine spécialisé en LISP qui à priori devrait se montrer très rapide. et c'est bien la CAS mais le rapport gain de puissance/coût (le processeur ne peut pas servir à autre chose) c'est toujours montré favorable à une implémentation logicielle.
A+JYT
Des machines avec processeurs dédiés... Ce n est pas déjà en route depuis un moment ? Il suffit de mettre quatre cœurs, deux gpu, un processeur plus faible pour chaque petite tache...
Je suis très très loin d'être un spécialiste, mais je suis d'accord avec cette analyse, et ça fait un petit moment que les choses s'orientent de cette façon.
ça s'est d'abord fait de façon discrète, avec des processeurs dédiés : les GPU, les processeurs physiques (comme l'Ageia PhysX), les puces H264.
puis ça a glissé dans les processeurs, avec la multiplication des unités vectorielles (2 dans l'Emotion Engine de la PS2, 6 dans le Cell de la PS3) puis le processeur GPU le la PS2 a été fondu avec le CPU.
nVidia a eu sa GeForce 9400 (ION) avec les contrôles E/S intégrés.
et depuis peu, Intel et AMD font de même avec CPU et GPU
sans parler des SoC ARM et l'A4 comme magnifique représentant.
ça va clairement dans cette direction, au moins pour les machines individuelles. les serveurs, c'est une autre affaire...
Selon ma comprehension, ce que dit cet article dans les très grandes lignes, c'est que Apple a eu tord de passer sur des processeurs X86 alors que les PPC, de part leur architecture, ont l'air plus adaptés aux futures évolutions.
Après, ce n'est que ma manière de voir la chose...
Amiga forever !
Atari forever !
@ dariolym
En même temps, si Apple n'était pas passée sous Intel, rien ne dit que ses ordinateurs auraient autant de succès qu'actuellement !
Entre faire un mauvais choix ou arrêter les ordinateurs, je prend largement l'option mauvais choix !
De toute manière, Apple a la transition dans ses gènes, s'il fallait un jour changer de plate-forme processeur, ce ne serait sans doute pas si douloureux que ça !
Amstrad 464 forever !
... Je suis déjà sorti...
oui et non on va déjà dans cette direction
que ce soit les cpu et les gpu elle restent très généraliste
par exemple dans un PC aujourd'hui on as une carte réseau qui gère la couche physique du protocole la couche au dessus (data) est géré par le driver la carte assure juste l'interface entre la couche physique et la couche data au niveau soft embarqué dans la carte. tout le reste est dans le driver donc traité par le CPU
on pourrait très bien imaginer que la carte assure des fonction jusqu'à des niveau plus hauts. le CPU s'en trouvant déchargé. cette partit pourrait être assuré par un proc dédié et câblé beaucoup plus spécialisé qu'un X86
ça demande de repenser la machine dans son ensemble car dans si on fait ça les échange entre la carte et la CPU ce n'est pas écrire des paquet de données dans à une adresse (interne) de la carte mais appeler méthode comme "ouvrir socket"
en supposant que j'ai une machine avec les composant Hard adéquat
ma carte réseau reçois un flux H.264 qu'elle transmet au décodeur H.264 qui envois le signal audio à la carte audio et le signal vidéo à la carte vidéo
Le Proc n'a rien à faire si ce n'est initier le process
le pipeline en place il se roule les pouces.
aujourd'hui on n'est pas tout à fait comme ça
c'est le proc qui dirige la carte réseau il copie les donnée reçu dans la mémoire si le PC est équipé d'une carte de décodage H.264 il indique à la carte la zone de mémoire à lire et la zone où placer le résultat ...
Oui un vas vers ça mais pour l'instant on laisse le proc être un point de passage obligé
les anciens se souviennent du SCSI cette norme d'échange entre périfs avait un mode de fonctionnement où un scanner pouvait écrire sur le disque sans passer par l'ordi quasi inexploité mais très efficaces le mac donnait l'ordre au disque d'attendre les donne du scanner et donnait ensuite la main au scanner
il est libre pour tout autre chose pb pas de preview mais super pour les gros volume
A+JYT
@ sekaijin > d'après ton exemple, et si j'ai bien compris, le cablage interne d'un ordinateur devrait être beaucoup plus important que actuellement, car il ne serait plus en étoile autour du processeur (en gros), mais tous les composants devraient être inter-connectés.
Hors, le câblage interne est une chose qui commence déjà à "poser problèmes" (voir les essais / réalisations de LightPeak par INTEL pour passer en fibre...), ne serai-ce pas encore augmenter le risque de problèmes que d'augmenter le nombre et la longueur des connections?
A moins que l'idée soit de garder un câblage interne en étoile mais de faire transiter les informations par le processeur "sans les traiter", ce qui risquerai de mener à une saturation rapide du bus système...
Enfin, in fine, il me semble que le problème n'est pas si simple, mais il est clair qu'il y a matière à mieux faire, entre autre en utilisant plus de "systèmes experts" qui savent faire une seule chose, mais beaucoup plus vite (Principe de l'architecture RISC en gros).